
The Organisational Response: Job Redesign for the AI Age
The complete organisational methodology for AI workforce transformation. Four-Column Task Decomposition, Five Roles as labour functions, the explicit transition methodology — co-creation, dual-track migration, the Trainer Paradox — and a 12-month implementation roadmap with cost model.
The Organisational Response: Job Redesign for the AI Age
C4AIL Whitepaper III
Status: Working draft — canon-consolidated (June 2026) Date: 1 April 2026 (revised 28 June 2026) Publisher: AI Guildhall (ai-guildhall.org) - the C4AIL practitioner community Lead author: Ethan Seow (C4AIL)
Relationship to prior papers:
- Whitepaper I (“Sovereign Commandthe state where an org owns its AI-informed decisions, can defend them, and can scale them without losing control; human judgment kept above machine fluency. The outcome ARGS produces. "Not…See full entry →”) defines what AI-ready leadership looks like - the Four Pillars (ARGSAgency (the decision to engage/interrogate, an environment you build), Architecture (Logic Pipes + clean data), Governance (the accelerator, not the brake), Scaling (decoupling output from…See full entry →), the Orchestrator role, the FloorFloor = the 90-95% who work through AI (mass literacy, 3-6 months); Ceiling = the 5-10% who design and govern AI: Architects, Orchestrators, Trainers (years).See full entry →/Ceiling model, Decision Survivabilitythe governance test: not "was it correct?" but "can you defend the *process* by which it was made, even after it goes wrong?" You can only defend what you were able to verify. Scales across…See full entry →.
- Whitepaper II (“The Labour Architecture”) diagnoses why the workforce is misarchitected - the Four Labourswork decomposed by the human it requires: Intellectual (weightless, commoditised by AI), Physical (atom-bound, lags), Accountability (presence-bound, the durable monopoly), Architectural…See full entry →, the Human Capability Stackseven layers of workforce capability: Psychological Foundation, Skills Architecture, Labour Types, Credentialing, Organisational Architecture, Education & Development, Economy & Policy.…See full entry →, the Accountability Gap, the 70-20-10 collapse, and the cross-civilisational design constraints.
- This paper answers the question both papers leave open: how does an organisation actually restructure its roles, workflows, and human pipeline around the diagnostic findings?
Executive Summary
The world has successfully reskilled billions of people. Japan, South Korea, Singapore, and China each transitioned entire populations between fundamentally different types of work within a single generation. None produced a published methodology for how to do it. The transition pedagogy was always tacit - embedded in institutional containers (military conscription, corporate lifetime employment, national narratives of collective upgrading, peer networks on factory floors) that did the developmental work invisibly.
AI is the first transition in history that simultaneously demands large-scale reskilling AND destroys the institutional containers through which reskilling has always occurred. The 70-20-10 model - the empirical finding that 70% of professional development occurs through on-the-job experience - is collapsing as AI automates the junior work that was the experiential mechanism. The institutional containers are failing: lifetime employment is weakening, corporate identity is eroding, and national narratives cannot articulate what AI-age work looks like clearly enough to hold populations through the transition. For the first time, the transition pedagogy must be made explicit.
The current landscape offers sophisticated tools for every step except the one that matters. Task decomposition (Jesuthasan & Boudreau, Mercer, ILO) identifies which tasks to automate. Skills frameworks (CompTIA, SFIA, ESCO) describe the destination roles. Consulting frameworks (McKinsey, BCG, Bain) manage the transformation project. Government programmes (SkillsFuture, Kurzarbeit, flexicurity) fund the journey. But the actual developmental process - how a professional transitions from one type of work to a fundamentally different type - is a void. Every framework’s Step 3 is “reskill the workforce,” and the methodology for that step is conventional corporate training with a 10-20% transfer rate (Baldwin & Ford, 1988; Blume et al., 2010).
The labour reorganisation this paper prescribes is not arbitrary: it exists because AI exhausts the explicit, and the competitive moat inverts toward the irreducibly human — accountability, judgment, architectural design — the macro-thesis set out in moat-inversion.md. This paper takes that inversion as given and answers the operational question it leaves open: how an organisation rebuilds its roles and pipeline around the human capacities that now carry the value.
This paper fills the void. It makes three contributions:
First, the labour type distinction. The Four-Column Task Decompositionsort every task into Automated-Intellectual, Automated-Physical, Elevated (needs MORE human judgment), New (Architectural, did not exist before). Extends other frameworks by asking "what…See full entry → extends existing frameworks by sorting human tasks into accountability labour (requiring judgment, ownership, and consequences) and architectural labour (designing and governing AI systems). These require fundamentally different development - accountability takes years and depends on identity formation; architectural thinking is a cognitive shift from execution to design. Every other framework lumps them as “human” and prescribes the same reskilling for both.
Second, the Five RolesFloor User (L0-2, works through AI, validates output, the backbone), Translator (L2-3, bridges domain + AI), Architect / Amplifier (L3-4, builds Logic Pipes / CAGE templates / verification…See full entry → model. Floor User, Translatordomain-fluency + AI-fluency + judgment + legibility; a trait overlaying every seat (meant to distribute), not a maturity rung. Commands a ~15-25% premium. Failures: fluent mistranslator /…See full entry →, Architect, Orchestrator, and Trainer - defined by labour function, not job title. Each role has specified hiring criteria, evaluation metrics, career paths, and - critically - a transition requirement that identifies whether the shift is additive (skills challenge, conventional training works) or transformative (identity challenge, developmental support required).
Third, the explicit transition methodology. Drawing on transfer-of-training science, developmental psychology (Kegan, Mezirow), identity research (Delfino et al., Ibarra, Bridges), evaluation evidence (J-PAL, MDRC, Mathematica), and the cross-civilisational design constraints from Whitepaper II, this paper codifies what TWI, Toyota Kata, guild apprenticeships, and medical residency programmes did tacitly - and adapts it for a world where the institutional containers no longer function. The methodology includes: the co-creation modelAI does the volume, the junior does judgment under a senior who develops their taste; the volume-to-judgment ratio inverts to 30/70 from day one.See full entry → for junior development (replacing volume work with judgment work from day one), the dual-track migration (Floor mass literacy in 3-6 months; Ceiling capability development over years), the Trainer Paradox and bootstrap (find the existing L4+ practitioners, build outward), and the private guild (embedding the five design constraints within an organisation’s own structure).
The paper also provides the HR operationalisation: performance metrics by labour type, compensation models, three legitimate career tracks, a governance model that separates system design authority from people management, and a 12-month implementation roadmap with cost estimates benchmarked against German dual system data, corporate learning averages, and enterprise AI infrastructure spending.
The honest constraint: this is a prescriptive framework grounded in existing evidence, not a validated methodology. The transition methodology is a synthesis - the individual components are published and peer-reviewed; the integration is an original contribution. Eight specific limitations and their corresponding research questions define the empirical programme required to move from framework to validated model.
Part I: The Tacit Pedagogy
1.1 The Largest Reskilling in History - With No Published Method
The world has successfully reskilled billions of people.
Japan transitioned tens of millions from agricultural labour to precision manufacturing between 1950 and 1980, producing the quality revolution that reshaped global industry. South Korea moved an entire population from subsistence farming to heavy industry to electronics to services in four decades - the fastest sustained economic transformation in recorded history. Singapore deliberately transitioned its workforce four times in a single generation: from entrepot trading to manufacturing, from manufacturing to services, from services to knowledge economy, and now from knowledge economy to AI-augmented work. China moved 200 million rural workers into factory employment in the span of twenty years, the largest peacetime labour migration in human history.
Every one of these transitions worked. None of them produced a published methodology for how to transition a human being from one type of work to a fundamentally different type of work.
This is the most important fact about reskilling that nobody discusses. The question is not whether large-scale workforce transition is possible - the evidence is overwhelming that it is. The question is how it was done. And the answer, in every case, is the same: the transition pedagogy was tacit. It was embedded in institutional containers that did the developmental work invisibly, without anyone extracting the methodology or writing it down.
1.2 The Institutional Containers
Japan imported Training Within Industry (TWI) from the United States in the early 1950s and evolved it into something more powerful: QC Circles (which transitioned over 5 million shop-floor workers from task executors to problem-solvers by the late 1980s, according to JUSE records), the Toyota Production System (which embedded continuous improvement as a daily practice, not a training event), and Toyota Kata (which Mike Rother finally codified in 2009 - sixty years after the practice began). The pedagogy was real. It was never extracted from the production system that contained it.
South Korea used a hidden bridge that no workforce development paper has ever named: military conscription. By the time Park Chung-hee’s Heavy and Chemical Industrialisation drive (formally launched in 1973) was recruiting agricultural workers into the chaebol factories, virtually every male worker had already completed military service. The military had already performed the hardest part of the transition - breaking the identity of the village farmer and reconstructing it around institutional discipline, standardised procedures, and hierarchical accountability. The chaebol training institutes (Hyundai’s mock-up ship sections, Samsung’s Blue Book SOPs) built technical skills on top of a psychological foundation the military had already laid. Nobody published a “Military-to-Factory Transition Manual.” The mechanism was invisible because it was structural.
Singapore built the most sophisticated workforce development infrastructure in the world - the Skills Development Fund (1979), the Institute of Technical Education, the WSQ framework, SkillsFuture - but every one of these is a funding and certification mechanism, not a transition pedagogy. They define what workers need to learn. They do not codify how a human being psychologically transitions from one professional identity to another. Singapore’s actual transition mechanism was the national narrative itself - the shared story of survival, vulnerability, and collective upgrading that gave every citizen a framework for understanding why their work was changing and what they were becoming. Lee Kuan Yew’s genius was not educational policy. It was providing an identity container large enough to hold an entire population through repeated disruption.
China’s 200 million rural-to-factory migrants transitioned through social networks - earlier migrants teaching newcomers - and firm-level military-style discipline. There was no published methodology, no pedagogical framework, no transition support system. The mechanism was peer transmission embedded in dormitory life and production lines. It worked at staggering scale. It was brutal, it was informal, and it left no documentation.
1.3 The One Published Methodology
The exception that proves the pattern is TWI itself - the Training Within Industry programme developed by the US War Manpower Commission between 1940 and 1945. TWI produced published manuals with a structured 4-Step Method (Prepare, Present, Try Out, Follow Up) explicitly designed for occupational transition: farmers, housewives, and office workers into industrial roles. It trained millions. It became the foundation on which Japan built its entire quality revolution. And it was dissolved after the war ended.
Charles Allen’s 4-step vocational instruction method (1919) preceded TWI and provided its intellectual foundation. Toyota Kata codified a related practice sixty years later. QC Circles were documented in JUSE manuals. These are the closest things to published transition pedagogies that exist in the global literature.
Sullivan and Al Ariss (2021), writing in the Human Resource Management Review, explicitly identify occupational transitions as “under-theorized.” Acemoglu and Autor, the most cited labour economists of the past two decades, treat the actual process of reskilling as a black box in their task-based economic models - they theorise the impact of technology on labour but assume the transition process is handled by “education supply.” Frey (2019), in The Technology Trap, argues that historical transitions are traps precisely because we focus on the policy of replacement rather than the pedagogy of transition - and that it took three generations for wages to rise after the first Industrial Revolution because nobody developed a systematic approach to workforce transition.
1.4 The Current Landscape: Everything Except the Hard Part
The AI workforce transformation landscape is sophisticated, well-funded, and structurally incomplete.
Task decomposition is well-served. Jesuthasan and Boudreau’s Work Without Jobs (2022, updated 2025) provides the gold standard for deconstructing jobs into tasks and reconfiguring them around automation. Mercer’s Deconstruct-Redeploy-Reconstruct framework operationalises this for HR departments. The ILO’s Refined Global Index decomposes work using 30,000 task categories. Stanford’s Brynjolfsson has built AI-Task Compatibility Matrices. The O*NET-based exposure analyses (Eloundou et al., 2023; Felten et al., 2023) score every occupation for automation potential.
Consulting frameworks provide enterprise-level guidance. McKinsey’s Rewired is the most detailed, with a six-dimension framework and a capability academy model. BCG’s Deploy-Reshape-Invent model identifies that 70% of AI transformation is people and process, not technology. Bain demonstrates that synchronising workflow and workforce modernisation produces 25-30% productivity gains versus 10-15% for tools-only deployment. Accenture has trained 550,000 employees on GenAI fundamentals.
Skills frameworks - CompTIA, SFIA, ESCO, O*NET, SkillsFuture’s Sector Skillthe smallest teachable unit -> a cluster integrated through practice -> an integrated set applied to a domain.See full entry → Councils - provide detailed competency taxonomies for the destination roles.
Government programmes - SkillsFuture, Kurzarbeit, Trade Adjustment Assistance, the Nordic flexicurity models, France’s Compte Personnel de Formation - provide funding at national scale.
What none of these provides is a methodology for the step that determines whether the transformation succeeds or fails: how to transition a human being from one type of work to a fundamentally different type of work.
Skills frameworks describe the destination. Task decomposition identifies the route. Consulting frameworks manage the project. Government programmes fund the journey. But the actual developmental process - how a compliance officer who has spent fifteen years writing reports becomes a professional who sets the intent for AI-generated reports and takes accountability for the outcome - is a void in the published literature.
Every framework’s Step 3 is some version of “reskill the workforce” - and the methodology for that step is assumed to be conventional corporate training: courses, workshops, certifications, learning journeys. The transfer-of-training literature shows why this assumption fails. The developmental psychology literature shows why it cannot work even when the training is well-designed. Part II addresses both.
1.5 Why This Paper Exists Now
Every previous workforce transition left the learning infrastructure intact. When agricultural workers moved to factories, the factory itself became the learning environment - on-the-job training, supervision, graduated responsibility. When manufacturing workers transitioned to services, the service environment provided the same function. When analog workers went digital, the digital tools were layered onto existing work processes, and workers learned by doing.
AI is the first transition in history that simultaneously demands large-scale reskilling AND destroys the mechanism through which reskilling has always occurred.
Whitepaper II demonstrated that the 70-20-10 model - the empirical finding that approximately 70% of professional development occurs through on-the-job experience, 20% through social learning, and 10% through formal training - is collapsing under AI. The 70% experiential component is being automated away: when AI handles the junior work, the junior has nothing to learn from. The 20% social component is being degraded: senior mentors are overwhelmed, the middle layer is being hollowed out. What remains is the 10% formal training - which has an 85-90% transfer failure rate when used alone.
The institutional containers that embedded transition pedagogy tacitly are also failing. Lifetime employment - Japan’s identity container for sixty years - is weakening. Corporate identity as a psychological anchor is eroding across all economies. Military conscription does not prepare workers for knowledge-work transitions. National narratives of collective upgrading require a shared understanding of what the population is upgrading to - and nobody can articulate what AI-age work looks like clearly enough to build that narrative.
For the first time, the transition pedagogy must be made explicit - because the systems that used to do it invisibly no longer function.
This paper makes it explicit.
Part II: Why Reskilling Fails
2.1 The Transfer Problem
Baldwin and Ford’s landmark 1988 review catalysed a field-wide consensus that has hardened over subsequent decades: formal training transfers to job performance at rates commonly estimated at 10-20%. This figure, widely cited across the training literature as a generous upper bound, has been reinforced by Blume, Ford, Baldwin and Huang’s 2010 meta-analysis and reaffirmed by Ford, Baldwin and Prasad’s 2018 thirty-year retrospective. The exact percentage is less important than the consistent finding: the vast majority of what people learn in formal training does not change how they work.
The finding is not that training is useless. It is that formal training - courses, workshops, certifications, e-learning - produces knowledge acquisition that rarely translates into sustained behavioural change on the job. The strongest predictor of transfer is not training design. It is work environment: supervisor support, opportunity to practice, and organisational climate for applying new skills (Ford, Baldwin & Prasad, 2018). This means that the most important variable in reskilling is not what happens in the classroom. It is what happens when the worker returns to the job.
The Blume et al. (2010) meta-analysis adds a critical distinction: open skills transfer less reliably than closed skills. Closed skills are procedural - how to operate software, how to follow a compliance checklist. Open skills are adaptive - how to exercise judgment, how to interpret ambiguity, how to make decisions under uncertainty. AI-reconfigured roles demand predominantly open skills. The compliance officer whose report-writing is automated needs to develop regulatory judgment, architectural thinking, and the capacity to take accountability for AI-generated output. These are open skills. The transfer literature predicts they will transfer from formal training at rates well below the already-poor 10-20% baseline.
No published study has measured transfer rates for AI-specific reskilling programmes. This is a striking gap. Organisations are spending billions on AI training with no empirical basis for believing the training will change how people actually work.
2.2 The Identity Problem
The most important recent finding in reskilling research comes from Delfino et al. (NBER Working Paper 34633): perceived identity fit is the single most important factor in willingness to reskill. Workers will pay to reskill into identity-congruent fields but require compensation for identity-incongruent transitions. This is not a preference. It is a structural constraint on workforce transformation.
The finding validates what career transition researchers have argued for decades. Ibarra’s Working Identity (2003) demonstrates that career transitions are identity work, not skill acquisition. People do not change careers by learning new skills and applying them. They change careers by experimenting with possible selves, testing provisional identities, and gradually reconstructing their professional narrative. The process takes years, not months, and it fails when organisations treat it as a training problem.
Schlossberg’s Transition Theory identifies four factors that determine transition outcomes: Situation, Self, Support, and Strategies. Only the last - strategies - maps to what conventional reskilling programmes provide (courses, workshops, coaching). The first three - the nature of the disruption, the person’s psychological resources, and the quality of social support - are treated as externalities. They are not externalities. They are the primary determinants.
Bridges’ Managing Transitions (2009) makes the distinction that organisations consistently miss: change is external (the new role, the new workflow, the new technology), but transition is internal (letting go of the old identity, navigating the neutral zone of uncertainty, and eventually embracing the new beginning). Organisations manage change. They rarely manage transition. The result is that the external change is implemented - new tools deployed, new workflows activated, new job descriptions published - while the internal transition stalls. People sit in new roles with old identities, performing the motions of the new work while psychologically anchored to the old.
2.3 The Developmental Problem
The deepest layer of the reskilling failure is developmental, not psychological. Whitepaper II established that approximately 58% of adults have not reached Kegan’s Stage 4 (Self-Authoring mind), based on composite data from Subject-Object Interviews with middle-class, college-educated US adults (Kegan, 1994; Kegan & Lahey, 2009; corroborated by Torbert, 1987). The general population figure is likely higher.
Stage 4 is the developmental threshold at which a person can hold their own values and standards as object - can examine them, question them, and reconstruct them. Below Stage 4, professional identity is fused with professional activity. “I am what I do” is not a metaphor; it is the structure of meaning-making. When the activity changes - when AI automates what I do - the identity is threatened at a level that no amount of reassurance, rebranding, or reskilling can reach.
Mezirow’s transformative learning theory (1991, 2000) describes how adults change fundamental meaning-making frames through a process he calls “perspective transformation.” This process requires a disorienting dilemma (the trigger), critical reflection on assumptions (the work), rational discourse with others undergoing similar transformation (the social component), and action on the new perspective (the integration). The process cannot be compressed into a workshop. It requires sustained engagement over months or years.
The AI workforce transition is, for a substantial portion of the workforce, a transformative learning challenge - not an additive learning challenge. The difference matters. Additive learning adds new skills to an existing identity: “I am a compliance officer who now also knows how to use AI tools.” Transformative learning reconstructs the identity itself: “I am no longer a person who writes compliance reports. I am a person who governs compliance outcomes.” These require fundamentally different pedagogical approaches. Every reskilling programme in the current landscape uses additive learning methods for what is, for many workers, a transformative learning challenge. This is why they fail.
2.4 The AI-Specific Problem
Previous workforce transitions were additive for most workers. The factory worker who learned to operate CNC machines was still a factory worker. The office worker who learned to use spreadsheets was still an office worker. The journalist who moved from print to digital was still a journalist. The core professional identity survived the technological change. New skills were layered on top.
AI is different because it automates the activity that defines the professional identity. The compliance officer’s identity is built on writing compliance reports. The junior lawyer’s identity is built on legal research and drafting. The financial analyst’s identity is built on building models and producing analysis. When AI handles these activities, the identity has no anchor.
This is compounded by the 70-20-10 collapse documented in Whitepaper II. The 70% experiential component - learning by doing the work - was the tacit mechanism through which professional identity formed. The junior who spent five years writing compliance reports did not just learn compliance. They became a compliance professional. The identity and the skill developed together, through the same experiential process. When AI automates the junior work, it does not just remove a training opportunity. It removes the identity-formation mechanism.
The result is a workforce where the destination roles require a fundamentally different professional identity, the training methods have a 10-20% transfer rate for the skills those roles demand, and the experiential mechanism through which identity naturally forms has been automated away.
This is why conventional reskilling fails at the AI transition. Not because the training is poorly designed. Not because the workers are resistant. Because the transition is developmental and the methods are additive. Because the identity must be reconstructed and the programmes only add skills. Because the experiential pathway no longer exists and nothing has replaced it.
2.5 What the Evaluation Evidence Shows
The evaluation evidence - rigorous, peer-reviewed, and consistently ignored by corporate reskilling programmes - points toward a clear set of principles.
J-PAL’s 2022 evidence review of randomised controlled trials found that sectoral employment programmes - combining upfront screening, sector-specific technical training, and soft skills development - are the most effective approach to occupational transition. The key features: they select for fit (not just willingness), they train for a specific destination (not generic skills), and they integrate interpersonal development with technical training.
MDRC’s longitudinal evaluations of transitional jobs programmes found that transitional jobs - temporary paid work in a new field - dramatically improve outcomes during transition but gains taper within several years without continuous coaching. The implication: experiential learning works, but it requires sustained developmental support to produce lasting change.
Mathematica’s 2012 evaluation of Trade Adjustment Assistance found that TAA participants had lower earnings than the comparison group four years after displacement. Long training without integrated transition support produced worse outcomes than no programme at all. The lock-in effect - extended training that delays re-employment without improving capability - is a real and documented risk.
Abt Global’s 2022 meta-analysis of 46 evaluations found that career pathway programmes increase employment in the target sector but do not improve earnings unless the transition targets “launchpad occupations” - roles with genuine upward mobility built into the structure.
Evaluations of Danish active labour market policies - among the most rigorous in the world, drawing on complete population registers - consistently find that private-sector programmes (learning while working in the new context) produce substantially larger effects than classroom-based training for workers changing sectors (Aarhus University/national labour market evaluations).
The evidence converges: experiential learning in the destination context, combined with sustained developmental support, identity-integrated design, and sector-specific focus, produces successful transitions. Classroom training, generic upskilling, and additive skills programmes do not.
These findings have not been synthesised into a prescriptive methodology. They sit in evaluation reports, read by policy researchers, ignored by the organisations designing AI reskilling programmes. Part V of this paper performs the synthesis.
2.6 The Forge
Part II has demonstrated that reskilling fails because the transition is developmental and the methods are additive, the identity must be reconstructed and the programmes only add skills, and the experiential pathway no longer exists. But diagnosing why reskilling fails does not answer the harder question: what replaces the master-apprentice chain when experts are scarce?
The history of professional education has produced two models. The Guild integrated tacit knowledge, explicit knowledge, and professional identity in a single environment — master-apprentice, community of practice, consequential work. It produced the full stackthe total infrastructure substrate development requires (educational + community + meaning layers); C4AIL owns "roughly a quarter" (the educational, high-leverage slice).See full entry →. It could not scale. One master, a few apprentices. Geographic lock. Its infrastructure survives in Germany and Switzerland; it has been destroyed in most of the world.
The Factory scaled the explicit layer. Bloom’s Taxonomy (1956) was the engineering solution for expert scarcity: when you don’t have enough masters, you intellectualise. You codify what can be codified, build curricula, standardise assessments, and deliver to millions. This was not a mistake — it was necessary. Without the explicit foundation, the tacit cannot develop. But the factory produces intellectual labour only. No tacit capability, no professional identity, no accountability. Its output — the explicit knowledge transfer that justified its existence — is now commodity. AI makes Combination (Nonaka’s explicit→explicit mode) essentially free.
The guild can’t scale. The factory’s output is free. What’s the third model?
The Forge. Guild → Factory → Forge. Raw material transformed through heat and pressure. Constraint is the mechanism, not the obstacle. High risk, high reward — what comes out is stronger than what went in.
The Forge is not theoretical speculation. It is the empirically observed pattern by which communities develop world-class expertise without access to the traditional expert pipeline. Mongolian wrestlers who dominated Japanese sumo. Cuban boxers who won 41 Olympic golds under a trade embargo. Japanese distillers whose whisky now outscores Scotch. Korean entertainment executives who studied Motown, systematised what Motown did intuitively, and created K-pop. Nigerian Scrabble players who reframed a vocabulary game as mathematics and beat native English speakers. Icelandic football coaches who invested in coaching education density — one qualified coach per 500 people versus England’s one per 10,000 — and took a nation of 330,000 to the World Cup. In every case, the periphery surpassed the centre. In every case, the mechanism was the same.
The Forge operates through seven steps:
- Intellectualise. Bloom’s contribution — codify what can be codified. Make the organic reproducible. Without intellectualisation, you get talent but not a pipeline.
- Reverse-engineer expert output. Study what experts do — their raw decisions, architectures, performances — not pre-digested textbook summaries. The periphery’s distinctive capability: conscious study of what the centre does unconsciously. The factory broke this by waiting for “verified experts” to approve curricula, introducing a 3-5 year lag that ensures content is always behind the bleeding edge.
- Convert through deliberate practice. Ericsson’s deliberate practice combined with Chi’s self-explanation effect. The learner must generate explanations, not receive them. Exams test exam-taking ability; they do not test accountability or the ability to deliver. The factory replaced the conversion mechanism with measurement, and the measurement displaced the mechanism.
- Build community. Scenius — peer-based expertise development when no single master is available. This requires structural prerequisites that many countries have systematically destroyed: unscheduled time for organic interaction, third spaces for informal gathering, and legal permission to associate without institutional gatekeeping. Germany’s 620,000+ voluntary associations (Vereine), Stammtisch culture, and Wanderjahr tradition provide distributed, resilient community infrastructure. The UK tried to rebuild vocational training six times without rebuilding community infrastructure; each attempt failed. Singapore graded community participation through the LEAPS framework, commercialised its third spaces, and regulated organic association — and now its youth report higher loneliness than its elderly. You cannot build training infrastructure without community infrastructure.
- Create consequential stakes. Real outcomes with real consequences — including the reality that luck plays a part. Sanitised assessments remove randomness; professional work does not. The factory replaced consequential stakes with grades — artificial stakes where nobody depends on what the student produces.
- Preserve expert access for calibration. Not for teaching — many experts cannot articulate how they got there (Polanyi’s point). For entrustment: “would I trust this person?” (ten Cate’s A-RICH). The expert’s job in the Forge is to say “yes” or “not yet.” Communities built around intuitive leaders who cannot articulate their own expertise fail because the leaders produce post-hoc rationalisations, not the actual mechanism. The Forge doesn’t rely on experts to teach. It uses them for calibration.
- Separate measurement from development. When the institution that teaches also certifies, the curriculum collapses to what the test measures. Germany’s IHK chambers examine; the Berufsschule teaches. Medical residency separates training from licensing. The factory merged them. Bloom’s Taxonomy intellectualised learning outcomes — necessary — but over 70 years the institution forgot what the outcomes were for. The cognitive domain became the entire definition of education. The tacit, embodied, and accountable dimensions were dropped — not because anyone decided they didn’t matter, but because the institution could only see what it could measure.
Steps 1-6 are the learning mechanism. Step 7 is the institutional safeguard against the corruption of institutionalisation — the pattern by which codification becomes the goal, uncodifiable dimensions are dropped, and the institution produces graduates who satisfy the framework but lack the essence. This corruption destroyed Bloom’s, Olympic judo, MTV-era pop, and competency-based medical education (until ten Cate’s EPAs corrected it). The Forge must be designed to resist it.
The full theoretical foundation, empirical evidence (ten cases across six domains), community infrastructure analysis (eight countries), philosophical framework (control vs seeding), and honest constraints are developed in Whitepaper V: The Forge — Professional Education When Experts Are Scarce and Content Is Free.
The Forge is what this paper prescribes. Parts III-V define the organisational structures, role architectures, and transition methodologies through which the Forge operates. Part VI defines the governance model — including the structural separation of measurement from development — that prevents the Forge from collapsing into another factory.
Part III: The Labour Type Distinction
3.1 The Missing Column
Every existing task decomposition framework sorts work into two or three categories. Jesuthasan and Boudreau use Automate / Augment / Redistribute. Mercer uses Substitute / Augment / Human-Led. The ILO uses exposure gradients from high to low. The underlying logic is binary: this task goes to the machine, that task stays with the human.
The question none of them asks is: what kind of human does the remaining task require?
Whitepaper II introduced the Four Labours model: Intellectual (weightless, commoditised by AI), Physical (atom-bound, converging with robotics), Accountability (presence-bound, the durable human monopoly), and Architectural (design-bound, the growth category). The reason the human-side columns hold the value is the macro-thesis of moat-inversion.md: as AI exhausts the explicit, the competitive moat inverts toward the irreducibly human, so Accountability and Architectural labour are not residue left after automation but the categories into which value relocates. This taxonomy transforms the decomposition from a binary sort into a diagnostic that determines everything downstream - what kind of development the person needs, what timeline it requires, and what institutional support must exist.
3.2 The Four-Column Task Decomposition
The Four-Column model extends the standard task decomposition by adding labour type headers to the human-side columns:
| Column 1: Automated (Intellectual) | Column 2: Automated (Physical) | Column 3: Elevated (Accountability) | Column 4: New (Architectural) |
|---|---|---|---|
| Tasks AI handles directly | Tasks robotics handles | Tasks requiring human judgment, ownership, and consequences | Tasks designing and governing the AI systems |
| Report generation, data analysis, routine drafting, research synthesis, pattern recognition | Warehouse sorting, routine inspection, assembly, logistics routing | Regulatory interpretation, risk judgment, client relationship ownership, ethical decisions, the signing momentthe formal, irreversible threshold where accountability becomes personal ("I built this, I stand behind it"); "would you sign this?" replaces "did you catch the errors?"See full entry → | CAGEthe front half of directing AI: Context (all situational/institutional/domain context), Align (the AI plays back its plan before running), Goals (granular, incl. the Must NOT / Must FLAG…See full entry → template design, verification engine construction, Logic Pipe architecture, workflow governance |
| Goes to machine | Goes to machine (2-5 year lag) | Stays with human - requires accountability development | New human work - requires architectural capability |
The critical insight is in Columns 3 and 4. Every other framework lumps them together as “human” or “augmented.” But they require fundamentally different capabilities, develop on different timelines, and demand different pedagogical approaches.
Column 3 (Accountability) tasks require the professional to own outcomes, exercise judgment under ambiguity, and bear consequences. The development path is slow - years, not months - because it depends on experiential learning, identity formation, and the developmental stages Whitepaper II documented (Body - Feel - Accept - Think - Choose). You cannot course-deliver someone into accountability. You can only develop them through graduated autonomy, consequential decisions, reflective practice, and community.
Column 4 (Architectural) tasks require the professional to design systems - to think in workflows rather than interactions, to encode domain knowledge into machine-readable structures, and to govern the systems they build. The development path is faster than accountability but slower than skills training, because architectural thinking is a cognitive shift, not a knowledge addition. It requires the transition from “how do I do this task?” to “how do I build a system for this task?” This is Kegan’s Stage 3 to Stage 4 transition applied to work design.
3.3 Worked Example: The Compliance Officer
To make the decomposition concrete, consider a compliance officer in a mid-sized financial services firm. Before AI, she spends her time roughly as follows:
| Activity | % of Time | Labour Type |
|---|---|---|
| Scanning regulatory updates | 15% | Intellectual |
| Drafting gap analyses | 10% | Intellectual |
| Writing compliance reports | 15% | Intellectual |
| Site inspections | 10% | Physical |
| Interpreting regulatory ambiguity | 15% | Accountability |
| Making enforcement decisions | 10% | Accountability |
| Designing audit methodologies | 10% | Architectural |
| Training junior staff | 5% | Accountability |
| Stakeholder communication | 10% | Mixed |
After the Four-Column decomposition:
Column 1 (Automated - Intellectual): Regulatory scanning, gap analysis, report drafting - 40% of her time. AI handles this. The output is faster, more comprehensive, and more consistent than human effort.
Column 2 (Automated - Physical): Not applicable for this role (site inspections remain human for now, though IoT sensors may shift some to Column 2 on a longer timeline).
Column 3 (Elevated - Accountability): Interpreting regulatory ambiguity where the answer is not in the text. Making enforcement decisions that balance compliance against business reality. Judging when a technical pass actually signals systemic risk. Training junior staff to develop the same judgment. This is 30% of her pre-AI time, but it becomes the centre of her post-AI role.
Column 4 (New - Architectural): Designing the compliance automation architecture. Building the verification engine that validates AI-generated compliance reports. Constructing the audit trail that proves the AI’s work is trustworthy. Setting the CAGE specifications that constrain what the AI produces. This is 10% of her pre-AI time (she was already doing some of this implicitly when she designed audit methodologies). It becomes 25-30% of her post-AI role.
Site inspections remain (10%). Stakeholder communication shifts from “presenting findings” to “translating AI-generated findings into business context” - which is accountability labour, not intellectual.
The post-AI compliance officer is a fundamentally different professional. She does not write reports; she governs the system that writes them. She does not scan regulations; she sets the standards for what the scanning system must catch. She does not produce analysis; she takes accountability for the analysis the machine produces.
This is not a promotion. It is a labour type shift - from intellectual labour (producing the output) to accountability labour (owning the outcome) plus architectural labour (designing the system). The question is: how do you develop a person who has spent fifteen years in Column 1 work into someone who can operate in Columns 3 and 4?
That question - which no existing framework answers - is what the Five Roles model and the transition methodology address.
Part IV: Five Roles as Labour Functions
4.1 From Job Titles to Labour Functions
Traditional organisational charts describe reporting lines and job titles. They do not describe what kind of labour each role performs. In the AI age, this distinction is the difference between a functioning organisation and a PowerPoint transformation that never leaves the slide deck.
The Five Roles model replaces the job-title approach with a labour-function approach. Each role is defined by its primary labour type, its position on the C4AIL maturity scale, and its relationship to AI systems.
4.2 Role 1: Floor User (L0-2)
The Floor User works through AI-structured interfaces, validates suggestions, and executes within defined boundaries. This is not a lesser role. It is the backbone. Ninety to ninety-five percent of the enterprise operates here, and the enterprise literally cannot function without it.
What they do: Process AI-generated output within structured workflows. Validate recommendations against domain knowledge. Flag anomalies for escalation. Execute standard operating procedures enhanced by AI assistance.
What they do not do: Design workflows. Override AI recommendations without escalation. Make autonomous decisions with significant consequence.
Primary labour type: Intellectual (transitioning from manual execution to AI-assisted execution with domain-grounded validation).
Hiring criteria: Domain knowledge (they must know enough to validate), interrogation skills (they must ask the right questions of AI output), validation discipline (they must not accept the first answer). Together these are the Verification Capacitythe competency that performs epistemic labour: epistemic depth (an oracle to check against), metacognitive calibration (when to trust the machine), and the disposition to engage rather than…See full entry → the framework names: the competency AI adoption requires more of, not less - the capacity to judge AI output, detect fluent-but-wrong, and engage effortfully rather than defer.
Career path: Floor User - Translator (if they develop bilingual capability) - Architect (if they choose the technical path). Not everyone moves up, and that is explicitly legitimate. Whitepaper I’s “Choice to Have a Life” is operationalised here as a respected career track.
Evaluation: Measured on validation accuracy, interrogation quality, and throughput. NOT measured on volume of AI output generated or number of prompts run.
Transition requirement: Additive. The Floor User adds AI fluency and validation discipline to existing domain expertise. This is a skills challenge, not an identity challenge, for most workers. Conventional training works here - the transfer-of-training limitations are manageable because the skills are relatively closed (follow this workflow, check against these criteria) and the professional identity is preserved (“I am still a compliance professional; I now use better tools”).
4.3 Role 2: Translator (L2-3)
The Translator bridges domain knowledge and AI capability. This is the universal skill identified in Whitepaper I, now operationalised as a role. The Translator makes AI output legible to domain experts and domain requirements legible to AI systems.
A clarification the Five Roles can otherwise obscure: “Translator” here names the seat where the trait-conjunctionthe bundle AI supercharges (substrate + mastery of directing AI + motivation); not a property of seniority.See full entry → (domain fluency + AI fluency + judgment about what matters) is the primary, full-time function. It is not a separate ladder that everyone else opts out of. Translator capability is a trait that overlays every seat — the Floor User, the Architect, the Orchestrator all carry it — and it deepens along each person’s own route rather than diverting them onto a Translator track. The dedicated Translator seat exists where an organisation needs that bridging concentrated in one role; the underlying capability is meant to distribute, which is precisely the corrective the Atrophy Trappermanent delegation of judgment decays the org in three stages: cognitive offloading, loss of evaluative power, structural sclerosis.See full entry → below describes. (See ai-adoption-storyline.md Part 4: “Translator = traits, not a level.”)
What they do: Interpret AI output in domain context. Communicate AI capabilities and limitations to non-technical stakeholders. Identify where AI recommendations diverge from domain reality. Facilitate the conversation between what the technology does and what the business needs to decide.
Primary labour type: Mixed - intellectual (interpretation) and accountability (judgment about what matters).
Hiring criteria: Bilingual fluency (domain language AND AI capability language), communication skill, judgment about when AI output requires human review.
Career path: Translator - Architect (technical track) or Translator - Manager-of-Translators (leadership track).
The Translator premium: AI-skilled workers command significant salary premiums over non-AI peers - 28% according to Lightcast (2025), with PwC’s Global AI Jobs Barometer (2024) reporting premiums of 25% that year, rising sharply as AI adoption accelerates. That is the general AI fluency premium. The Translator-specific premium - for professionals who combine domain expertise with AI capability, not just AI fluency alone - is estimated at 15-25%, varying by sector and geography. This is an interpolation from the general premium data, not a directly measured figure; the Translator profile as defined here does not yet appear in published salary surveys. The premium exists because the capability is scarce: it requires enough technical understanding to interrogate AI output AND enough domain expertise to know what matters. Most professionals have one or the other. The Translator has both.
Transition requirement: Moderate. The Translator must develop bilingual fluency, which involves learning to think in two vocabularies simultaneously. This is a cognitive shift but not an identity disruption - the Translator retains their domain identity while adding a communication capability. Cohort-based development with mixed technical/domain participants works well here. Timeline: 3-6 months for functional bilingualism.
The Atrophy Trap (from Whitepaper I): Permanent dedicated Translators make organisations worse through cognitive offloading - Stage 1 (the organisation stops thinking about the domain because “we have someone for that”), Stage 2 (loss of evaluative power - without internal literacy, the organisation cannot distinguish good advice from bad), Stage 3 (structural sclerosis - processes hard-coded around the Translator’s presence). The solution is not a dedicated Translator role but Minimum Viable Literacythe distributed baseline AI literacy (enough not to be fooled) that the Atrophy Trap's fix requires; leaders' capacity to commission, interrogate, escalate.See full entry → distributed across the organisation, with Translator capability as a transitional function that builds organisational fluency over time.
4.4 Role 3: Architect / Amplifier (L3-4)
The Architect builds Logic Pipesengineered end-to-end deterministic workflows (generate -> verify -> triage -> review -> approve -> audit) that constrain and route AI, replacing narrative chatting.See full entry → (deterministic decision workflows that channel AI output through structured verification steps), CAGE templatesversioned repositories of validated reasoning chains (structure + constraints + quality bar + known failure modes).See full entry →, and verification enginesdeterministic (rule-based, not AI-judging-AI) checks that validate AI output against domain rules before human review.See full entry →. This is the hands-on builder who converts expert knowledge into deterministic workflows.
What they do: Design prompt templates and CAGE specifications. Build and maintain verification engines. Construct Knowledge Layerthe codified expert-knowledge specifications an Architect builds (operationally, the Institutional Vault); lets a task reduce from a paragraph of context to one sentence.See full entry → artefacts - what the operational frame names the Institutional Vaultthe org's codified, executable knowledge store (processes, records, prompts, pipelines) - surface made durable. The three-way line: Holding (frees judgment), Executing codified rules (the…See full entry → (the-institutional-vault.md): the codified, executable store the human Brainthe Brain (human judgment, verification, accountability) stays human and is never outsourced; the Vault holds and runs what is codified. "You don't build a second brain; you build an…See full entry → draws on but never delegates judgment to. Translate expert intuition into machine-readable logic. Test and iterate workflow designs.
Primary labour type: Architectural - designing the systems through which AI operates.
Hiring criteria: Domain expertise, architectural thinking (ability to design systems, not just use them), AI fluency at the building level (not just the using level).
Career path: Architect - Orchestrator. This is the critical pipeline. Orchestrators are developed from Architects over a 2-3 year period. They are not hired externally.
Evaluation: Measured on template quality, specification maintainability, verification engine effectiveness, and the ratio of human intervention required in their workflows.
Transition requirement: Transformative. The Architect must shift from “how do I do this task?” to “how do I build a system for this task?” This is the cognitive shift from execution to design - from the artisanal to the architectural. For professionals whose identity is built on expert execution (“I am the best at writing these reports”), this is an identity challenge: the value shifts from personal output to system output. Whitepaper I’s Sarah - the supply chain director who became an Orchestrator - navigated this transition over years, not months. The development pathway requires mentored practice in system design, progressive responsibility for workflow architecture, and a community of peers making the same transition. Timeline: 12-24 months to functional architectural capability; 2-3 years to readiness for Orchestrator pipeline.
4.5 Role 4: Orchestrator (L5-6)
The Orchestrator designs the system and governs the architecture. Defined in Whitepaper I (Part V) as the terminal evolution of the knowledge worker - this section adds the HR operationalisation.
What they do: Design end-to-end AI-augmented workflows. Set verification standards. Govern the Queue Aroute AI output by confidence: A auto-approved + logged, B Translator-reviewed, C escalated to Architect/Orchestrator.See full entry →/B/C triage system. Make architectural decisions about which work is automated, which is elevated, and which is new. Coach and develop Architects.
Primary labour type: Accountability - they own the system-level outcome.
Span of control: The Orchestrator’s leverage comes from designing systems, not supervising individuals. In well-designed systems, one Orchestrator can govern workflows serving 50-200+ Floor Users. High-complexity domains (healthcare, financial regulation) require tighter ratios because the verification architecture must account for more edge cases and the consequences of failure are more severe. These are design heuristics based on early implementations, not established benchmarks.
Hiring: Develop from Architects over 2-3 years. Do NOT hire externally. The Orchestrator must have built the systems they now govern - they must have earned the right to sign off through progressive accountability, not credentials. This is ten Cate’s entrustment model applied to organisational design.
Compensation: Premium role, tied to verified output metrics rather than hours worked. The Orchestrator is evaluated on system-level outcomes, not personal productivity.
Transition requirement: Deeply transformative. The Orchestrator must have completed the execution-to-design shift (Architect stage) and then completed a second shift: from designing systems to governing them and taking accountability for their outcomes. This requires Kegan’s Stage 4 (Self-Authoring) at minimum. The Orchestrator’s identity is built on system-level accountability - “I own the outcome of this system” - which requires the developmental capacity to hold one’s own values and standards as object, examine them, and take responsibility for their consequences. The pipeline is long because it cannot be shortened: 2-3 years from Architect to Orchestrator readiness, with progressive exposure to consequential decisions and real accountability.
4.6 Role 5: Trainer / Capability Builder
The Trainer maintains and grows the human pipeline. This is the role most organisations forget and the role without which the entire model fails.
What they do: Run development programmes. Staff the AI Guildhall Studio (the supervised practice space described in WP7). Mentor juniors through the accountability development pathway. Facilitate after-action reviews. Model the vulnerability and presence that developmental relationships require.
Primary labour type: Accountability - they are accountable for the development of other humans.
Hiring criteria: L4+ practitioners who can teach, not just do. The Trainer must have crossed the accountability threshold themselves - they must have signed off, lived with the result, and developed the capacity to hold space for others doing the same.
Why this role matters: This is where the accountability pipeline lives. Without Trainers, the zone of proximal development collapses. AI handles the volume work; the Trainer ensures juniors still get the judgment reps. The Studio is not a classroom. It is a supervised developmental environment operating in Edmondson’s Learning Zone - high psychological safety AND high accountability simultaneously.
Transition requirement: The Trainer is not developed through a training programme. The Trainer is discovered - identified among existing L4+ practitioners who have both the accountability capability and the relational capacity to develop others. Part V addresses the Trainer Paradox: the system needs Trainers to produce accountable practitioners but cannot produce Trainers without already having accountable practitioners.
4.7 The Five Roles Are Not an Org Chart
The Five Roles do not replace the existing management hierarchy. They overlay it. A compliance officer who becomes a Floor User still reports to the Head of Compliance. A senior developer who becomes an Architect still sits within the engineering department. The roles describe what kind of labour a person performs, not where they sit on the org chart.
This distinction matters because it prevents the most common transformation failure: creating a parallel AI organisation that competes with the existing structure. The Five Roles are a lens for understanding what kind of development each person needs, what kind of work they perform, and how their contribution is measured. They do not require reorganisation. They require reclassification - seeing the workforce through labour type rather than job title.
Part V: The Explicit Transition Methodology
5.1 What This Section Does
This section codifies what TWI, Toyota Kata, Korean military-to-factory transitions, guild apprenticeships, and medical residency programmes have done tacitly - and adapts it for a world where the institutional containers that embedded these pedagogies no longer function.
The methodology draws on:
- The transfer-of-training evidence (experiential learning in the destination context produces transfer; classroom training does not)
- The identity research (Delfino et al.: identity fit determines willingness; Ibarra: transition is identity work; Bridges: change is external, transition is internal)
- The developmental psychology (Kegan: stage transitions require confirmation, contradiction, and continuity over years; Mezirow: transformative learning requires disorienting dilemma, critical reflection, rational discourse, and action)
- The evaluation evidence (J-PAL: sectoral focus works; MDRC: experiential learning without coaching tapers; Mathematica: training without integration produces negative outcomes)
- The cross-civilisational design constraints from Whitepaper II (embodiment over credentialing, community of mutual obligation, mechanisms for detecting degradation, developmental sequencing that cannot be compressed, human agency at every level)
5.2 The Dual-Track Migration
The workforce does not move as one. It moves in two tracks with fundamentally different timelines, mechanisms, and success criteria.
Track 1: Floor (Mass Literacy). Timeline: 3-6 months. Target: the 90-95% who will work through AI-structured interfaces. Mechanism: structured interface adoption, validation skills training, domain-specific AI literacy. Success criteria: the user can validate AI output against domain knowledge, flag anomalies, and use structured workflows effectively.
This track is achievable through conventional training - courses, workshops, on-the-job practice. The transition is additive (adding AI fluency to existing domain expertise) rather than transformative (reconstructing professional identity). The transfer-of-training limitations are manageable because the skills are relatively closed and the work environment can be structured to support application. CompTIA AI Essentials provides a certification waypoint.
Track 2: Ceiling (Capability Development). Target: the 5-10% who will become Architects, Orchestrators, and Trainers. Mechanism: identify L3 candidates (existing senior professionals with architectural thinking), Architect development programme, progressive accountability, Orchestrator pipeline. Success criteria: the practitioner can design, build, and govern AI-augmented workflows AND take responsibility for their output.
This track cannot be achieved through courses alone. The transition is transformative — it requires the identity shift from execution to design to governance. It requires the five accountability mechanisms documented across the historical and cross-civilisational evidence: graduated autonomy, consequential decisions, reflective accountability, the signing moment, and community of practice. CompTIA AI Architect+ and SecAI+ provide certification waypoints for the technical component. The accountability component is validated through portfolio review.
Critically, Track 2 is not a single timeline. It splits into two sub-tracks depending on where the candidate is starting from — and conflating them is the most consistent source of miscalibrated organisational planning.
5.2.1 The Adjacency Pathway
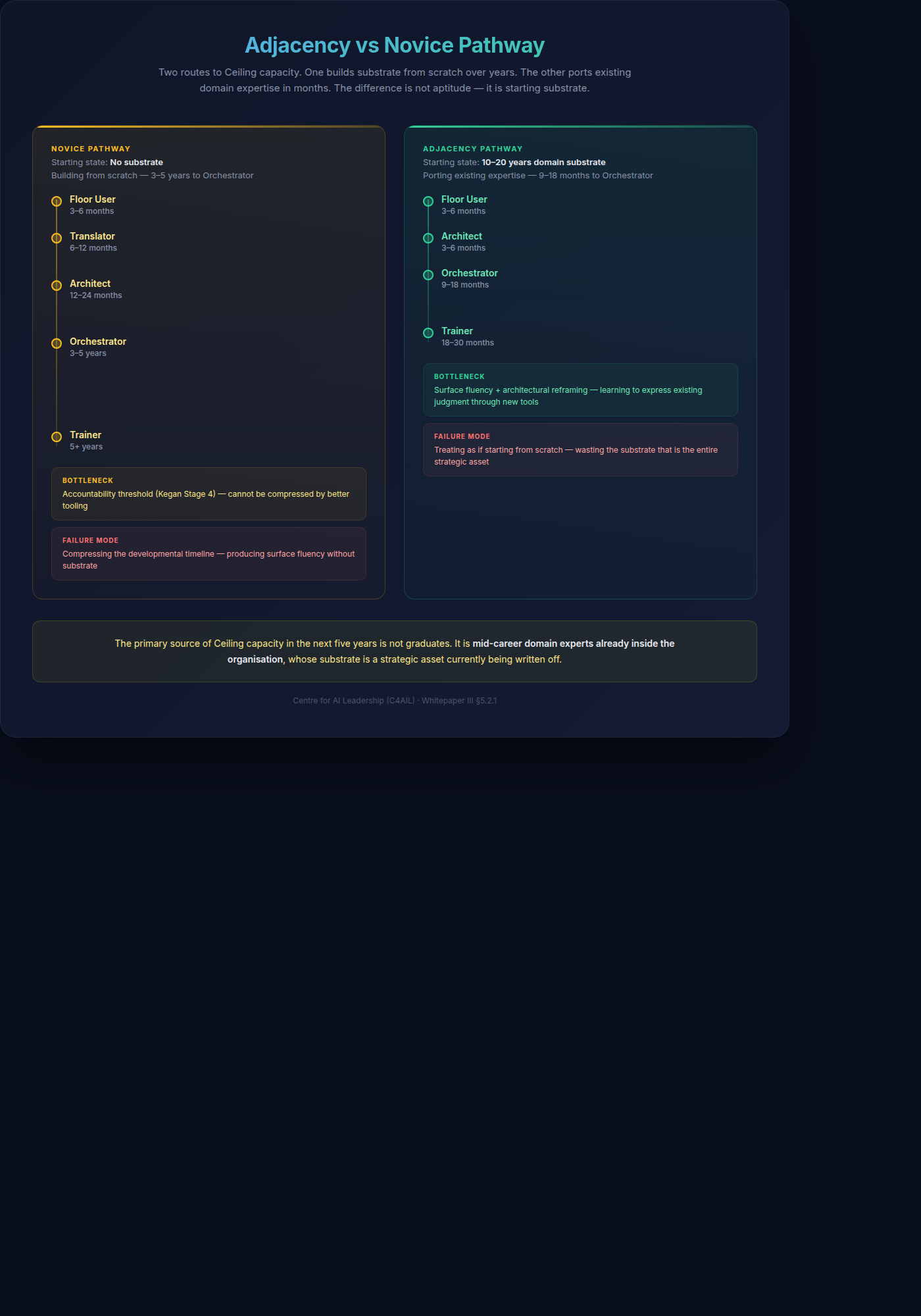
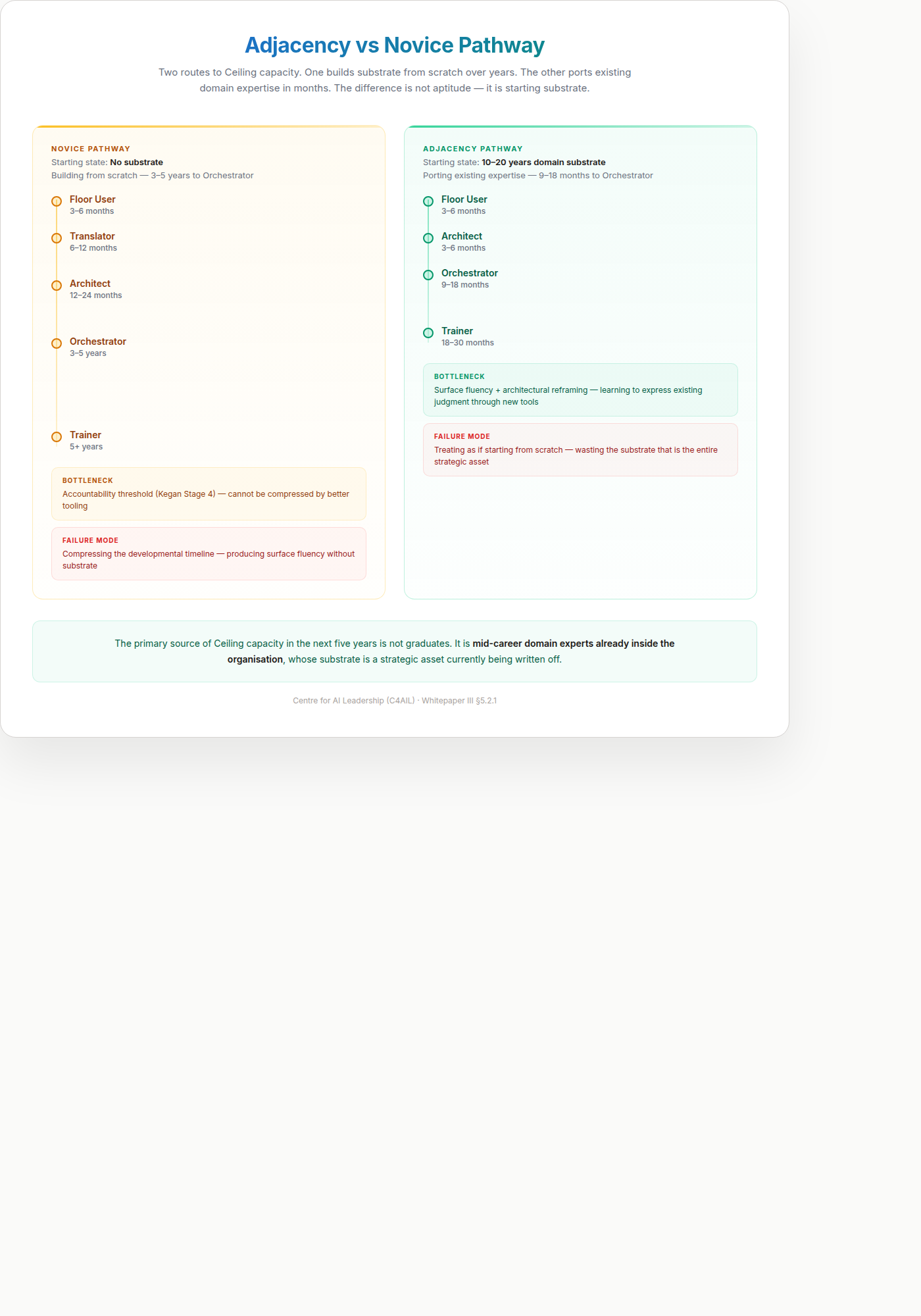
Whitepaper II §1.6 introduced the distinction between substrate (tacit domain knowledge, accountability experience, mental representations, peer-calibrated judgment) and surface (tools, interfaces, workflows, vocabulary). That distinction is load-bearing here. The Ceiling track has two very different populations, because substrate and surface develop on different timescales.
The Novice Pathway (3-5 years). A candidate who does not yet have substrate in any domain is building both layers in parallel from scratch. They need the full developmental sequence: exposure to consequential work, pattern library accumulation, peer calibration, the five accountability mechanisms, and time. The 3-5 year timeline for Orchestrator readiness is real for this population — and non-negotiable, because it tracks the rate at which human judgment and identity transform under consequential stakes. No amount of curriculum compression shortens it.
The Adjacency Pathway (9-18 months). A candidate who already has 10-20 years of substrate in their domain — a senior analyst, a mid-career lawyer, a veteran auditor, a practising clinician, a senior engineer — is not building substrate. They are porting it. Their pattern library, accountability experience, and peer-calibrated judgment transferred into the AI-augmented version of their work the moment the surface changed. What they need is a much narrower intervention: the new surface layer (AI tools, prompting, workflow redesign), the architectural vocabulary to design systems rather than execute tasks, and calibration exercises that bridge their existing substrate into the new context. The literature on expert transfer is unambiguous: when the underlying representations transfer, learning the new surface is a matter of months, not years (Chi 1988; Ericsson 2006; Chase & Simon 1973).
The two pathways differ at every level:
| Dimension | Novice Pathway | Adjacency Pathway |
|---|---|---|
| Starting state | No substrate | Deep substrate in adjacent domain |
| Primary development task | Build substrate + learn surface | Port substrate + learn surface |
| Timeline to Architect | 12-24 months | 3-6 months |
| Timeline to Orchestrator | 3-5 years | 9-18 months |
| Bottleneck | Accountability threshold (Kegan Stage 4 transition) | Surface fluency + architectural reframing |
| Mechanism | Five accountability mechanisms + consequential work under Trainer | Structured surface exposure + cross-domain calibration + peer community |
| Failure mode | Compressing developmental timeline | Treating as if starting from scratch |
The industry routinely treats domain experts as if they are on the novice pathway — enrolling them in generic “AI upskilling” courses that assume no prior capability, then wondering why senior practitioners disengage. The problem is not their age, their motivation, or their “digital readiness.” The problem is that the programme is building the wrong thing. They already have substrate. They do not need another three years of it. They need the surface layer and the reframing — and if the programme delivers those, they cross into Architect and Orchestrator roles in a fraction of the time the novice pathway requires.
This has direct organisational implications. The primary source of Ceiling capacity in the next five years is not graduates. It is mid-career domain experts already inside the organisation, whose substrate is a strategic asset currently being written off. An Adjacency Pathway programme — targeted surface training, architectural vocabulary, peer community of similarly-ported experts, calibration work — unlocks this capacity at roughly one-quarter the time cost of developing novices, and delivers practitioners whose substrate is already calibrated to the organisation’s actual domain rather than to generic curriculum exemplars. This is the population the Guildhall (WP7) is primarily built to serve.
The Novice Pathway still matters. Some Ceiling candidates will come through it, particularly for new domains where no adjacent expert population exists. But for every domain where mid-career experts already exist in the organisation, the adjacency pathway is both faster and structurally better grounded — because the substrate is real, not manufactured.
5.3 The Co-Creation Model: Solving the Missing Middle
Whitepaper II’s diagnosis of the Missing MiddleAI hollows the journeyman tier where substrate is built (the "barbell": gains at floor and ceiling, squeeze in the middle); no juniors today, no seniors in five years.See full entry → - juniors replaced by AI, the accountability pipeline destroyed - requires a specific solution. The solution is not to resist automation of junior work. It is to redesign the junior role around co-creation.
The old model: Junior does volume work - develops pattern recognition over 5 years - earns graduated autonomy - crosses the accountability threshold.
The AI-age model: AI does the volume work. Junior co-creates with AI under senior supervision.
This distinction matters. The junior does not simply review AI output for errors - that is still reception, still Freire’s banking model (education as deposit-and-retrieval, described in Whitepaper II) with a faster deposit machine. The junior creates with AI as a tool: drafts the contract using AI, then defends the choices - why this clause structure, why this risk allocation, what this protects the client from. The senior’s role is not to check accuracy (AI handles that). The senior’s role is to develop the junior’s taste - the felt sense of what constitutes good work versus work that merely satisfies requirements.
The question shifts from “did you catch the errors?” to “would you sign this?” From accuracy to judgment. From reception to creationthe foundational education change AI demands; the "missing verb" that develops accountability.See full entry →.
The volume-to-judgment ratio inverts: instead of 90% volume / 10% judgment, the junior operates at 30% volume / 70% judgment from day one. Co-creation is the mechanism. Taste is what develops. The junior who co-creates with AI for two years under a senior who has taste emerges with something no amount of AI review could produce: an internal standard for quality that precedes articulation - phronesisthe felt sense of quality (practical wisdom) that separates the competent from the accountable; AI has episteme and techne but no phronesis.See full entry →, the practical wisdom that sits on top of episteme (knowing) and techne (doing) but cannot develop without having gone through both experientially.
The timeline compresses: junior to competent practitioner in 2 years instead of 5. But the compression only works if the creation is real - real work, real consequences, real names on the output. Without co-creation, you get a junior who has watched AI work for two years and can neither do the work nor judge the work.
The accelerated model requires more senior supervision, not less - which means Trainers (Role 5) become the critical bottleneck. And what Trainers provide is not instruction. It is the developmental environment in which taste grows: confirmation (“your instinct here was right - here’s why”), contradiction (“this looks right but it would fail in court - here’s what you’re not seeing”), and continuity (the sustained relationship that allows both). This co-creation-through-Trainer mechanism is the framework’s Capability Transferthe third path beyond DIY (slow) and outsource (atrophy): hire experts whose deliverable is building the capability inside the org. "Adopt can be bought; evolve must be built."See full entry → pipeline: the route by which substrate moves from those who hold it to those building it, replacing the volume-work apprenticeship the Missing Middle destroyed.
5.4 The Trainer Paradox and the Bootstrap
The model creates a circularity this paper must name honestly. Trainers must be L4+ practitioners who have crossed the accountability threshold. Whitepaper II demonstrated that approximately 58% of adults have not developed the psychological foundation for independent accountability - and that stage transitions take 5-10 years with the right conditions. So the system that needs Trainers to produce accountable practitioners cannot produce Trainers without already having accountable practitioners.
This is not a fatal flaw. It is a bootstrap problem - and bootstrap problems have a known solution: you start with the small number who already have the capability and build outward.
Every organisation has people who crossed the accountability threshold despite the system, not because of it. The surgical attending who trained through a real residency. The audit partner who signed off and lived with the result. The engineering lead who shipped a product and took the call when it broke. These people exist - they are just not identified, not valued for this specific capability, and not deployed as Trainers.
The first step is not to create Trainers from scratch. It is to find the ones you already have, name what they do, and redirect their capacity toward developing others.
The Guildhall community provides the second lever: cross-organisational mutual accountability. A single organisation’s pool of L4+ practitioners may be thin. A community of practice that spans organisations - where Trainers from different companies mentor each other’s juniors, review each other’s portfolios, and maintain shared standards - partially replicates the guild function that mandatory chambers provide at the national level. It is not a substitute for institutional infrastructure. But it is a better approximation than any individual organisation can build alone.
The timeline remains honest — but splits along the same novice/adjacency line introduced in §5.2.1. The first generation of Trainers is found, not developed: L4+ practitioners who already have the substrate, identified and redirected. The second generation divides. Mentees coming through the Adjacency Pathway (mid-career experts porting existing substrate into Trainer capability) reach readiness in 18-30 months. Mentees coming through the Novice Pathway (candidates building substrate from scratch) take 5+ years. Systemic change — reaching enough Trainers that the system is no longer bottlenecked on them — takes a decade regardless, because scale is constrained by how many first-generation Trainers exist and how many mentees each can hold. Anyone promising faster across the board is selling courses, not building capability. Anyone denying that the adjacency track exists is wasting the strategic asset the organisation already has.
5.5 The Private Guild
An organisation cannot rebuild the guild infrastructure that Germany and Switzerland inherited from centuries of institutional evolution. But it can build a private guild - an internal system that embeds the five design constraints from Whitepaper II within its own structure.
Embodiment over credentialing. The portfolio systemthe medieval masterpiece modernised: real consequential work + structured reflection, judged by cross-org L4+ reviewers on "would we trust what you make?" (phronesis), not "did you pass?"…See full entry → replaces the examination system. Advancement to Ceiling roles requires demonstrated accountability - evidence that the practitioner has made consequential decisions and lived with the results. The question is not “did you pass the test?” but “would we trust what you make?”
Community of mutual obligation. The Studio, the Guildhall, and the after-action review create the developmental relationships that accountability requires. The master and the apprentice are accountable to each other - not to an institution that mediates between them. The Orchestrator who developed an Architect is invested in that Architect’s success. The Architect who was developed by an Orchestrator has a model for what good governance looks like. The relationship is direct, consequential, and bidirectional.
Mechanisms for detecting degradation. The challenge protocol, published corruption detection metrics, revenue-rigour decoupling, and the dissolution clause from C4AIL’s antifragile design ensure the developmental system does not follow the corruption arc that has consumed every previous institution (Whitepaper II, Part VII). The thing that makes money (the Studio, the programmes) and the thing that proves mastery (the Fellowship, the portfolio) are structurally separated.
Developmental sequencing that cannot be compressed — except where substrate already exists. Floor capability in 3-6 months. For candidates on the Novice Pathway: Architect pipeline in 12-24 months, Orchestrator readiness in 3-5 years, Trainer pipeline in 5+ years. For candidates on the Adjacency Pathway (§5.2.1) — mid-career domain experts porting existing substrate — the surface and architectural reframing collapse to 3-6 months for Architect and 9-18 months for Orchestrator, with Trainer readiness reachable in 18-30 months. The novice timelines are not conservative estimates to be optimised; they are developmental realities constrained by the rate at which substrate is built under consequential stakes. The adjacency timelines are not shortcuts; they reflect the fact that the slow-developing layer (substrate) is already there, and only the fast-developing layer (surface) is being added.
Human agency at every level. From the first day, the junior makes choices, experiences consequences, and develops the felt sense of what good work requires. The co-creation model is not a passive apprenticeship. It is an active engagement where the junior’s choices - and their consequences - are the developmental mechanism.
5.6 Certification as Waypoints, Portfolio as Evidence
Certifications serve as objective markers of progress along the reskilling pipeline. They validate the technical component - the part that can be tested:
| Level | Role | Certification | What It Validates |
|---|---|---|---|
| L1-2 | Floor User | CompTIA AI Essentials | Baseline AI fluency, validation awareness |
| L3 | Architect | CompTIA AI Architect+ | Architectural capability, system design |
| L4+ | Security track | CompTIA SecAI+ | AI security governance, risk architecture |
| L3-5 | All Ceiling | C4AIL L3-5 Portfolio | Demonstrated accountability (portfolio-based, not exam-based) |
The critical distinction: certifications validate competence. They do not validate trustworthiness. The question for Floor roles is “can you do this?” The question for Ceiling roles is “would we trust you to do this unsupervised?” Only portfolio-based assessment - the Guildhall’s Level 3 Submissions and Level 4-5 Reviews - approaches the second question.
Part VI: The Organisation That Develops
6.1 Performance Management
The measurement system must align with the labour type, not the job title.
Floor Users are measured on validation accuracy (do they catch AI errors?), interrogation quality (do they ask the right questions?), and throughput (do they maintain pace within structured workflows?).
Architects are measured on template quality (do their designs work?), specification maintainability (can others use and extend their work?), and verification engine effectiveness (does the system catch what it should catch?).
Orchestrators are measured on system-level output (does the AI-augmented workflow produce verified value?), pipeline health (are Architects developing? Are juniors getting judgment reps?), and adaptation speed (how quickly does the system respond to changes?).
Trainers are measured on developmental outcomes: how many practitioners have they moved from one level to the next? What is the quality of portfolios produced by their mentees? Do juniors in their cohort reach the signing moment faster than the baseline? And critically, do the people they develop stay and develop others? The Trainer who produces Architects who produce the next generation of Trainers is the most valuable person in the system. This is the hardest role to measure because the outcomes are longitudinal - a Trainer’s real impact shows up 2-5 years after the developmental relationship, not in quarterly reviews.
What nobody is measured on: Hours worked. Volume of AI output generated. Number of prompts run. These metrics incentivise intellectual labour production - the exact thing being commoditised. Measuring prompts-per-day is like measuring keystrokes-per-hour in the typing pool.
6.2 Compensation
The compensation model reflects the shift in labour value.
Floor roles: Stable, predictable compensation with domain-expertise premiums. The Floor User with 20 years of regulatory knowledge is more valuable than the Floor User who can write better prompts, because domain knowledge is the validation substrate.
Architect roles: Premium compensation for architectural capability, tied to system output rather than individual productivity. The Architect who builds a verification engine that saves 10,000 review hours is compensated for the system outcome, not the hours they personally worked.
Orchestrator roles: Significant premium, performance-linked to verified business outcomes. The Orchestrator is the scarcest role and the highest-leverage - their value comes from designing systems that govern workflow quality at scale, not from personal output.
The Translator premium: Bilingual capability (domain + AI fluency) attracts a salary premium estimated at 15-25%, varying by sector and geography - an interpolation from the general AI-premium data (Lightcast, 2025; PwC Global AI Jobs Barometer, 2024/2025), not yet a directly measured figure for the Translator profile (see §4.3). The premium exists because the capability is genuinely scarce and immediately valuable.
6.3 Three Career Tracks
Three legitimate tracks, none subordinate to the others:
The Depth Track: Floor User - Senior Floor User - Domain Expert. For professionals who choose mastery within their domain and do not seek architectural or leadership roles. This is “The Choice to Have a Life” - operationalised as a legitimate career track with its own compensation ladder and recognition structure.
The Architecture Track: Floor User - Translator - Architect - Orchestrator. For professionals who develop both technical and accountability capability. The critical pipeline for organisational AI maturity. “Translator” appears here as a stage, but read it as a trait that deepens along this route, not a separate ladder anyone bypasses: Translator capability overlays every seat on the track (§4.3), so the progression is one person’s capability maturing, not a hand-off between distinct role-holders.
The Capability Track: Any level - Trainer. For professionals who have crossed the accountability threshold and can develop others. This track requires demonstrated accountability, not just technical expertise.
Promotion criteria: Portfolio-based, not tenure-based. The AI Guildhall provides the portfolio platform (Level 3 Submissions, Level 4-5 Reviews). CompTIA certifications provide objective technical waypoints. But advancement to Ceiling roles requires demonstrated accountability - evidence that you have made consequential decisions and lived with the results.
6.4 Governance Model
The governance structure operates through three layers:
Layer 1: Departmental line management (unchanged). Floor Users, Translators, and domain-specific Architects report through their existing departmental chains. Their performance is evaluated jointly: departmental managers assess domain output; the AI governance function assesses workflow compliance and verification quality.
Layer 2: AI governance function (new). A cross-functional body - typically reporting to the COO, CTO, or a dedicated CAIO - that owns the workflow architecture. Orchestrators sit here. Their responsibility is system-level: designing Logic Pipes, setting verification standards, governing Queue A/B/C triage, and making architectural decisions about what is automated versus elevated. The governance function does not manage people - it manages systems. Orchestrators govern workflows, not individuals. The canonical C4AIL CAIO is not a generic title for whoever owns AI: it is a Direct-seat Orchestrator measured by dispensability - succeeding by manufacturing Translator capability across the organisation rather than hoarding the bridge (“Kill the Buddha,” ai-adoption-storyline.md Parts 3-5). The AI governance function described here is, in its mature form, the structural body that role runs: the AI Centre of Excellence, the hub-and-spoke institution set out in ai-centre-of-excellence.md that scales substrate outward rather than centralising it - the organisational form of this Part VI.
Layer 3: Capability development (new). Trainers report through HR or a dedicated Learning & Development function, but operate embedded within departments - running the Studio, mentoring juniors, facilitating after-action reviews. The Trainer’s dual reporting reflects their dual function: administratively to L&D, operationally to the department where they develop practitioners.
The critical design principle: Separate the authority to design systems (Orchestrators, Layer 2) from the authority to manage people (departmental managers, Layer 1). When these are conflated - when the person who designs the AI workflow also manages the people working within it - the system optimises for compliance rather than capability. The Orchestrator must be free to redesign workflows without being constrained by headcount politics. The departmental manager must be free to develop people without being pressured to optimise for throughput.
Conflict resolution: When departmental priorities conflict with governance standards - a department wants to bypass verification steps to meet a deadline - the escalation path runs to the executive sponsor (CAIO or equivalent). The governance function has veto authority on verification standards but not on business priorities. This mirrors the relationship between a CFO’s financial controls and operational departments: the controls are non-negotiable, but what gets funded is a business decision.
6.5 The Credentialing Gap
The Five Roles model requires a credentialing layer that does not currently exist in any national framework.
Competency frameworks globally - the WSQ framework in Singapore, the European Qualifications Framework (EQF), the UK’s Regulated Qualifications Framework (RQF), SFIA for IT professionals, O*NET for occupational classification - share a common architecture. They decompose work into competency units, define each unit through knowledge statements and performance criteria, and assess through tests, observed demonstrations, or supervised workplace tasks. This architecture was designed for technical microskills: can this person configure a firewall, draft a contract to specification, operate this machine within tolerance? It works. For technical competence, it works very well. Singapore’s investment in this infrastructure is among the most substantial and sophisticated in the world.
What this architecture cannot do is validate accountability. The question “can this person configure a firewall?” has a testable answer. The question “would we trust this person to decide which firewall architecture protects our most sensitive assets - and to be accountable when the decision is tested by an actual breach?” does not. Accountability is not a competency unit. It cannot be decomposed into knowledge statements. It cannot be assessed through a test or a single observed demonstration. It can only be evidenced through a portfolio of consequential decisions made over time - decisions where the practitioner’s name was on the output, the stakes were real, and the outcome was lived with.
This is not a critique of existing frameworks. It is a recognition that they were designed for a different labour type. When the dominant labour type was intellectual - and the primary workforce development question was “can this person do this task?” - competency-based credentialing was the right architecture. Now that the dominant labour demand is shifting toward accountability and architectural labour - and the primary question is becoming “would we trust this person to govern this system?” - the credentialing architecture needs an additional layer.
The portfolio system proposed in Section 5.6 is that layer. It does not replace competency-based certification. It augments it. CompTIA AI Essentials validates that a Floor User can operate within AI-structured workflows. The C4AIL L3-5 Portfolio validates that an Architect or Orchestrator can design, build, and take accountability for those workflows. Both are needed. The first without the second produces technically capable professionals who cannot be trusted with system-level decisions. The second without the first produces judgment without grounding. The credentialing architecture must hold both.
6.6 Portfolio Assessment in Practice
The portfolio is not a collection of work samples. It is a curated body of evidence that demonstrates consequential judgment over time.
What goes in: Decisions the practitioner made where the outcome mattered. A verification engine the Architect designed and the results it produced in operation - including the failures and what was learned from them. A workflow the Orchestrator governed through a stress event - a regulatory change, a system failure, a novel case the automation could not handle. An after-action review the Trainer facilitated and the developmental outcomes it produced in the practitioners who participated.
What does not go in: Certificates of completion. Hours logged. Course transcripts. AI outputs generated. These evidence exposure, not accountability.
Who reviews: Peers and seniors who have themselves crossed the accountability threshold. Portfolio review is not grading. It is the question: “Would I trust this person with my clients, my systems, my reputation?” Only someone who has borne that weight themselves can answer it credibly. This is why the Guildhall’s review panels require L4+ practitioners - the reviewers must have the experiential foundation to evaluate judgment, not just competence.
The standard: The portfolio is assessed against the question “would you sign this?” - not “is this technically correct?” A technically correct verification engine that the Architect cannot explain, defend, or take responsibility for has not met the standard. A technically imperfect system that the Architect can explain, has iterated on, and takes ownership of is closer to the mark. The standard is accountability, not perfection.
Frequency: Portfolio submissions are developmental milestones, not annual reviews. A practitioner submits when they believe they have sufficient evidence of the next level of accountability - when they can demonstrate not just that they did the work, but that they owned the outcome. The timing is self-directed, with Trainer guidance.
Interface with national frameworks: Portfolio assessment is designed to complement, not compete with, existing competency-based credentials. In systems like SkillsFuture, where competency units and Statements of Attainment provide the technical validation layer, the portfolio provides the accountability layer on top. A practitioner can hold both: the competency credential that says “technically qualified” and the portfolio assessment that says “trusted to govern.” National frameworks that evolve to incorporate portfolio-based assessment for their higher-level qualifications would close the gap between what credentialing systems currently measure and what the AI-age workforce actually needs.
6.7 The Measurement Problem
The current measurement infrastructure for workforce development was built for a world where the question was: “Did people complete the training?”
The standard KPIs across corporate L&D and national workforce systems are: completion rates (did they finish the course?), assessment scores (did they pass the test?), participant satisfaction (did they enjoy it?), and employment outcomes (are they employed 6-12 months later?). These are Kirkpatrick Levels 1-2 at best - reaction and learning. They do not measure Level 3 (behaviour change on the job) or Level 4 (business results). The transfer-of-training evidence in Part II explains why: 80-90% of training does not transfer, so measuring completion tells you almost nothing about capability.
For the Five Roles model, the measurement problem is more fundamental. The KPIs that matter - judgment accuracy, accountability readiness, system-level output quality, pipeline health, developmental progression - are longitudinal, context-dependent, and resistant to standardisation. You cannot measure whether a Trainer is effective in a quarterly review. You measure it by tracking whether the practitioners they developed are producing accountable work three years later. You cannot measure whether the co-creation model produces better judgment than traditional training by giving both groups a test at the end. You measure it by tracking who reaches the signing moment, how quickly, and whether they can defend their decisions under scrutiny.
This creates a tension with the funding structures that support workforce development. Government programmes measure seat-hours, completion rates, and employment outcomes because these are measurable at scale, administratively efficient, and politically legible. Accountability development produces outcomes that are none of these things. The most important developmental outcome - a practitioner who can be trusted with consequential decisions - takes years to produce, cannot be standardised across contexts, and is invisible to administrative reporting systems.
The resolution is not to abandon administrative metrics. It is to layer accountability metrics on top. The organisation tracks both: the administrative KPIs that satisfy funders and regulators (completion, certification, employment) AND the developmental KPIs that predict actual workforce capability (portfolio quality, time to signing moment, judgment accuracy, Trainer multiplication rate, Orchestrator pipeline health). The first set proves compliance. The second set measures whether the transformation is working.
The accountability metrics are harder to collect, slower to mature, and impossible to game with volume. That is their value.
6.8 The Compliance Officer - Before and After
Returning to the worked example from Part III:
| Dimension | Before | After |
|---|---|---|
| Performance metrics | Reports produced, audits completed, hours logged | Judgment accuracy (did her interpretations hold up?), architecture quality (does her compliance engine work?), escalation hit rate (when she flags something, is she right?) |
| Compensation basis | Seniority + scope | Domain expertise premium + verified outcome metrics |
| Career path | Linear: more reports - bigger team | Branching: Depth (domain expert in regulatory interpretation) or Architecture (compliance system designer) |
| Development investment | Annual compliance update course | Co-creation with AI under senior regulatory counsel, portfolio of judgment calls reviewed by peers, Guildhall participation |
The volume metrics she was measured on - reports per quarter, audits per year - measured her intellectual labour output. That output is now AI’s job. If the HR system still measures it, it will either measure the AI’s productivity (meaningless) or incentivise her to bypass the AI and do the work manually (counterproductive). The new metrics must measure what she actually contributes: the judgment, the intent, the accountability.
Part VII: Implementation
7.1 Month-by-Month Sequencing
| Month | Action | Outcome |
|---|---|---|
| 1-2 | Task-level audit of top 10 roles (Four-Column Decomposition) | Clear map of which tasks are automated, elevated, and new |
| 2-3 | Identify Orchestrator candidates from existing senior staff (L4+ assessment); identify Adjacency Pathway candidates — mid-career domain experts with transferable substrate (§5.2.1) | Named pipeline of 3-5 Orchestrator candidates + 5-15 Adjacency candidates |
| 3-4 | Build Floor infrastructure (structured AI interfaces, Queue A/B/C triage, validation protocols) | Floor Users can work within governed AI workflows |
| 3-6 | Launch Adjacency Pathway cohort — substrate porting for identified domain experts (9-18 month track) | First Adjacency candidates begin supervised AI-augmented practice in their existing domain |
| 4-6 | Run first Architect development cohort (C4AIL programme or equivalent) — Novice Pathway | First cohort of 5-10 Architects building Logic Pipes |
| 6-9 | Deploy Floor to first department, measure baseline. Adjacency candidates producing governed AI workflows in their domain. | 10-15% productivity gains (tools-only baseline); Adjacency cohort approaching Architect-equivalent capability |
| 9-12 | Activate Ceiling — Orchestrators governing Logic Pipes and verification engines. First Adjacency graduates operating as domain-specific Architects. | 25-30% productivity gains (workflow redesign + capability) |
| 12+ | Scale to next department. Begin junior co-creation programme. Activate Trainer pipeline. Second Adjacency cohort. | Sustainable transformation with accountability pipeline intact |
7.2 Measurement Framework
| Metric | Baseline (Month 0) | Target (Month 12) | What It Measures |
|---|---|---|---|
| Productivity gain | 0% | 25-30% | Workflow redesign effectiveness |
| AI validation accuracy | Unknown | >95% | Floor User capability |
| Verification queue throughput | N/A | Measured | System capacity |
| Junior judgment reps per week | 0 | >10 | Accountability pipeline health |
| Architect pipeline size | 0 | 5-10 | Ceiling development |
| Orchestrator readiness | 0 | 1-2 candidates | Leadership pipeline |
7.3 Technology Requirements
The terms “structured AI interfaces,” “verification engines,” and “Logic Pipes” appear throughout this paper. This section specifies what they mean in concrete technology terms.
Structured AI interfaces (Floor infrastructure). The Floor User does not interact with a raw chatbot. They work through constrained interfaces that limit the scope of AI interaction to domain-valid operations. Technically: role-based prompt templates with pre-set system instructions, input validation schemas that reject out-of-scope requests, output rendering that surfaces confidence indicators, and audit logging that captures every human-AI exchange. These can be built on any enterprise LLM API (Azure OpenAI, AWS Bedrock, Google Vertex AI, or self-hosted models) using middleware frameworks. The key design principle: the Floor User’s interface should feel like a domain tool, not a general-purpose AI.
Verification engines (Architect-built). A verification engine is a deterministic check that validates AI output against domain rules before it reaches the human reviewer. Examples: a financial verification engine that confirms all figures trace back to source data; a legal verification engine that checks contract clauses against approved language; a compliance verification engine that cross-references AI recommendations against the current regulatory register. These are rule-based systems - not AI judging AI, but structured logic (decision trees, regex validation, database lookups, API calls to authoritative sources) applied to AI output.
Logic Pipes (the workflow layer). A Logic Pipe is an end-to-end workflow: generation - verification - triage - human review - approval - audit trail. The Queue A/B/C triage system sits within the Logic Pipe: Queue A (high-confidence, auto-approved with audit log), Queue B (medium-confidence, routed to a Translator for review), Queue C (low-confidence or novel, escalated to an Architect or Orchestrator). Logic Pipes are implemented as workflow orchestration using tools like Temporal, Apache Airflow, n8n, or custom state machines.
What this is NOT. This is not a recommendation to purchase a specific vendor stack. The technology is commodity - the hard part is the domain knowledge embedded in the verification rules, the triage thresholds, and the escalation logic. That domain knowledge is what Architects build and Orchestrators govern. The technology is the plumbing; the architecture is the design of the house.
7.4 Order-of-Magnitude Cost Model
No validated cost-benefit analysis exists for this framework (see Limitation #4). The following estimates are indicative, drawn from the German dual system (BIBB, 2022/23), corporate learning benchmarks (ATD, 2024), and consulting rate equivalents. They assume a 500-person enterprise deploying the Five Roles model.
| Cost Category | Year 1 | Years 2-3 | Basis |
|---|---|---|---|
| Floor deployment (AI tools, structured interfaces, validation training) | $130-210K | $50-100K/yr maintenance | Enterprise AI seat licences at $360-470/user/yr deployed to 60-80% of workforce + 2-day validation training per employee |
| Translator identification & development (assessment, domain-AI bridging workshops) | $80-120K | $40-60K/yr | Assessment instruments + cohort-based development (15-25 Translators at $5-8K each) |
| Architect development (mentored pipeline, portfolio system, Studio infrastructure) | $120-200K | $150-250K/yr | 5-10 Architects at $15-25K development cost each + L4+ mentor time (opportunity cost) |
| Trainer capacity (L4+ practitioners allocated to development) | $50-100K | $200-400K/yr | Opportunity cost: 10-20% of senior practitioner time redirected from production to development |
| Community infrastructure (Guildhall participation, portfolio platform, quarterly assessments) | $30-50K | $20-40K/yr | Platform costs + facilitation + CompTIA/C4AIL certification fees |
| Total Year 1 | $410-680K | ||
| Total ongoing (Years 2-3) | $460-850K/yr |
Context: A 500-person enterprise making even a modest on-premise AI infrastructure investment (one 8-GPU node plus cloud API access) is spending $500K-800K on infrastructure in Year 1 alone. Enterprises pursuing serious deployment are spending $2.5-4.5M on hardware before a single workflow is redesigned. For every dollar spent developing the humans who use AI, most enterprises spend three to five dollars on the machines themselves.
This ratio inverts what the evidence suggests. Only 12% of companies have achieved AI maturity (Accenture, 2022, N≈1,200). Eighty-two percent of early-maturity companies have no talent strategy for AI (Accenture, 2024). The infrastructure investment is necessary. But infrastructure without human capability development is what leaves 95% of organisations seeing zero measurable P&L return from generative AI (MIT Project NANDA, The GenAI Divide, 2025). The proposed model does not replace infrastructure spending - it ensures the infrastructure produces returns.
German benchmark: EUR 26,200 gross / EUR 8,086 net cost per apprentice per year (BIBB, 2022/23). The net cost is low because apprentices produce value during training - productive output averages EUR 18,124 per apprentice per year. The same principle applies: Architects and Translators produce value while developing.
Per-employee cost: $820-1,360 per employee in Year 1 (500-person enterprise). ATD’s 2024 State of the Industry report benchmarks corporate learning spend at $1,283 per employee - this model is within the same range but redirected from courses to developmental infrastructure.
7.5 What This Roadmap Does Not Solve
This 12-month roadmap produces Floor capability and begins Architect development. It does not produce Orchestrators. It does not solve the Trainer Paradox at organisational scale. It does not build the institutional infrastructure that Germany and Switzerland inherited from centuries of guild tradition.
The roadmap is a first year, not a complete transformation:
| Timeline | What It Produces | What It Requires |
|---|---|---|
| Months 1-6 | Floor capability (validation, AI literacy) | Training - conventional, scalable |
| Months 6-12 | Architect pipeline (first cohort building systems) | Mentorship - requires existing L3+ staff |
| Years 1-3 | First Orchestrators (earned through progressive accountability) | Developmental environment - Studio, portfolio system, community of practice |
| Years 3-5 | Trainer pipeline (Orchestrators who can develop others) | Institutional commitment - sustained investment in human development despite ROI pressure to automate instead |
| Years 5-10 | Cultural shift (accountability as organisational identity) | Leadership patience - the hardest resource to secure |
The limitations of what a single organisation can achieve are real:
-
The poaching problem. Without mandatory chambers, Company A invests two years developing an Orchestrator; Company B hires them at a premium. Company A stops investing. The only organisational defence is to make the developmental environment itself part of the value proposition - people stay because the conditions for growth exist nowhere else.
-
The SME problem. The Five Roles model assumes enough internal depth to staff Architects, Orchestrators, and Trainers. A 20-person accountancy firm has no one to spare as a Trainer. A 30-person logistics company cannot justify a dedicated Orchestrator. The solution is external infrastructure - the AI Guildhall and industry-specific communities of practice serve as the shared developmental architecture that SMEs cannot build alone.
-
The civilisational pipeline. No country has successfully rebuilt guild infrastructure from scratch after destroying it. France is spending EUR 15 billion annually trying. The UK has failed six times in 40 years. The organisational solutions in this paper are the best available response, not a cure. They work for organisations willing to invest. They do not solve the civilisational pipeline problem.
Part VIII: Limitations and Research Agenda
This paper synthesises existing research into a prescriptive methodology. The synthesis is novel; the components are grounded in published evidence. The following limitations are acknowledged.
What This Paper Has Not Proven
1. No validated transfer rates for the co-creation model. The argument that co-creation (junior creates with AI under senior supervision) develops judgment faster than the traditional volume-based apprenticeship is theoretically grounded and consistent with the transfer-of-training evidence (experiential learning in the destination context produces better transfer). But no controlled study has directly compared co-creation-based versus traditional junior development on accountability outcomes.
Research needed: Quasi-experimental study comparing junior professionals trained through co-creation versus conventional training. Measure: judgment accuracy, accountability readiness (ten Cate EPA levels), time to signing moment, supervisor trust ratings.
2. The transition methodology is a synthesis, not an empirical finding. Part V assembles principles from transfer-of-training science, developmental psychology, identity research, evaluation evidence, and cross-civilisational analysis into a prescriptive methodology. The individual components are grounded. The synthesis is an original contribution that has not been validated as an integrated system.
Research needed: Pilot implementation in 3-5 organisations across different sectors. Measure transition outcomes (identity integration, skill transfer, accountability development) at 6, 12, and 24 months. Compare against organisations using conventional reskilling approaches.
3. The Five Roles model has no longitudinal validation. The model is logically derived from the Four Labours taxonomy and consistent with emerging workforce patterns. But no study has tracked whether organisations that adopt labour-function classification outperform those using traditional job-title approaches.
Research needed: Matched-pair organisational study comparing Five Roles adopters with conventionally structured comparators. Measure: AI maturity progression, productivity gains, talent retention, pipeline health, time to value.
4. No validated cost-benefit analysis. The cost model in Part VII is indicative, drawn from analogous programmes (German dual system, corporate learning benchmarks). No organisation has implemented this specific model and measured ROI.
Research needed: Track actual costs and measurable returns across pilot implementations. Develop an ROI model that accounts for the compounding value of capability development (Orchestrators who build better Floors which surface new Ceiling candidates).
5. The Trainer Paradox may be worse than described. The paper assumes that every organisation has L4+ practitioners who can be identified and redirected as Trainers. In some sectors - particularly those that have already experienced significant AI-driven restructuring - the L4+ population may be thinner than assumed. The bootstrap may not have enough seed capital.
Research needed: L4+ capability audit across sectors. Map the distribution of accountability capability by industry, firm size, and geography. Identify sectors where the Trainer Paradox is acute versus manageable.
6. No workforce voice. The paper prescribes a transition methodology without citing interviews, surveys, or qualitative data from people actually experiencing AI-driven role transformation. Whitepaper II acknowledged this same limitation. It remains unaddressed.
Research needed: Qualitative study - structured interviews with 50-100 professionals across 3-5 industries who have experienced AI-driven role changes. Map their reported experience against the paper’s predictions. Validate or revise the methodology based on what people actually report.
7. The SME gap is not solved. The paper acknowledges that the Five Roles model assumes organisational depth that SMEs do not have. The proposed solution (external infrastructure via the Guildhall) is asserted, not proven. No study has demonstrated that cross-organisational developmental infrastructure can substitute for internal capability in firms with fewer than 50 employees.
Research needed: SME pilot programme using Guildhall infrastructure as external developmental support. Measure whether SME participants achieve comparable Ceiling development to enterprise participants with internal infrastructure.
8. Cultural and jurisdictional variation is unaddressed. The methodology is presented as sector- and geography-agnostic. It is not. Union environments, regulated industries, collectivist cultures, and economies with strong state direction in workforce development will all require significant adaptation. Whitepaper II’s union analysis (Part V, Section 5.5) names this gap for organised labour specifically. The broader cultural adaptation remains unaddressed.
Research needed: Adaptation studies across jurisdictions - how does the transition methodology function in Germany (co-determination), Singapore (state-directed), the Nordics (flexicurity), and the Philippines (services economy with weak institutional infrastructure)?
The Research Partnership
These eight research questions define the empirical programme required to move this paper from prescriptive framework to validated methodology. The AI Guildhall, in partnership with CompTIA (workforce methodology and cross-industry access), CirroLytix (services economy data and Philippine workforce research), and ClassDo (programme development and credentialing innovation), proposes to conduct this research over a 24-month period beginning Q3 2026.
The first priority is Research Question 6 (workforce voice) and Research Question 2 (pilot validation) - because the first tests whether the methodology matches lived experience and the second tests whether it works as an integrated system. Everything else follows from those two.
Sources
C4AIL Framework
- C4AIL Whitepaper I: Sovereign Command: AI-Ready Leadership (2026).
- C4AIL Whitepaper II: The Labour Architecture: Redesigning Work for the AI Age (2026).
- C4AIL Whitepaper V: The Forge: Professional Education When Experts Are Scarce and Content Is Free (2026).
- C4AIL WP7: The AI Guildhall: Building What the Factory Cannot (2026).
Learning Science and Expert Performance
- Allen, C.R. (1919). The Instructor, the Man, and the Job. J.B. Lippincott.
- Bloom, B.S. (ed.) (1956). Taxonomy of Educational Objectives: The Classification of Educational Goals, Handbook I: Cognitive Domain. David McKay.
- Chase, W.G. & Simon, H.A. (1973). Perception in chess. Cognitive Psychology, 4(1), 55-81.
- Chi, M.T.H., Glaser, R. & Rees, E. (1988). The nature of expertise. In The Nature of Expertise (pp. xv-xxviii). Lawrence Erlbaum.
- Ericsson, K.A., Krampe, R.T. & Tesch-Römer, C. (1993). The role of deliberate practice in the acquisition of expert performance. Psychological Review, 100(3), 363-406.
- Ericsson, K.A. (2006). The influence of experience and deliberate practice on the development of superior expert performance. In The Cambridge Handbook of Expertise and Expert Performance (pp. 683-703). Cambridge University Press.
- Freire, P. (1970). Pedagogy of the Oppressed. Continuum.
- Nonaka, I. & Takeuchi, H. (1995). The Knowledge-Creating Company. Oxford University Press.
- Polanyi, M. (1966). The Tacit Dimension. University of Chicago Press.
- Rother, M. (2009). Toyota Kata: Managing People for Improvement, Adaptiveness and Superior Results. McGraw-Hill.
Transfer of Training
- Baldwin, T.T. & Ford, J.K. (1988). Transfer of training: A review and directions for future research. Personnel Psychology, 41(1), 63-105.
- Blume, B.D., Ford, J.K., Baldwin, T.T. & Huang, J.L. (2010). Transfer of training: A meta-analytic review. Journal of Management, 36(4), 1065-1105.
- Ford, J.K., Baldwin, T.T. & Prasad, J. (2018). Transfer of training: The known and the unknown. Annual Review of Organizational Psychology and Organizational Behavior, 5, 201-225.
Developmental Psychology and Transformative Learning
- Kegan, R. (1994). In Over Our Heads: The Mental Demands of Modern Life. Harvard University Press.
- Kegan, R. & Lahey, L.L. (2009). Immunity to Change: How to Overcome It and Unlock the Potential in Yourself and Your Organization. Harvard Business Press.
- Mezirow, J. (1991). Transformative Dimensions of Adult Learning. Jossey-Bass.
- Mezirow, J. (2000). Learning to think like an adult: Core concepts of transformation theory. In Learning as Transformation (pp. 3-33). Jossey-Bass.
- Torbert, W.R. (1987). Managing the Corporate Dream: Restructuring for Long-Term Success. Dow Jones-Irwin.
Identity and Career Transition
- Bridges, W. (2009). Managing Transitions: Making the Most of Change (3rd ed.). Da Capo Press.
- Delfino, A. et al. (2024). Identity and willingness to reskill. NBER Working Paper 34633.
- Ibarra, H. (2003). Working Identity: Unconventional Strategies for Reinventing Your Career. Harvard Business School Press.
- Schlossberg, N.K. (1981). A model for analyzing human adaptation to transition. The Counseling Psychologist, 9(2), 2-18.
- Sullivan, S.E. & Al Ariss, A. (2021). Making sense of different perspectives on career transitions: A review and agenda for future research. Human Resource Management Review, 31(1), 100727.
Labour Economics and Task Analysis
- Acemoglu, D. & Autor, D. (2011). Skills, tasks and technologies: Implications for employment and earnings. In Handbook of Labor Economics, Vol. 4B (pp. 1043-1171). Elsevier.
- Eloundou, T., Manning, S., Mishkin, P. & Rock, D. (2023). GPTs are GPTs: An early look at the labor market impact potential of large language models. arXiv:2303.10130.
- Felten, E., Raj, M. & Seamans, R. (2023). Occupational heterogeneity in exposure to generative AI. SSRN Working Paper.
- Frey, C.B. (2019). The Technology Trap: Capital, Labor, and Power in the Age of Automation. Princeton University Press.
- Jesuthasan, R. & Boudreau, J.W. (2022). Work Without Jobs: How to Redefine Work and Redesign Organizations. MIT Press.
Workforce Measurement and Assessment
- Edmondson, A.C. (2019). The Fearless Organization: Creating Psychological Safety in the Workplace for Learning, Innovation, and Growth. Wiley.
- Hodges, B. et al. (1999). OSCE checklists do not capture increasing levels of expertise. Academic Medicine, 74(10), 1129-1134.
- Kirkpatrick, D.L. (1994). Evaluating Training Programs: The Four Levels. Berrett-Koehler.
- ten Cate, O. (2005). Entrustability of professional activities and competency-based training. Medical Education, 39(12), 1176-1177.
Evaluation Evidence
- Abt Global (2022). Meta-analysis of 46 career pathway programme evaluations.
- J-PAL (2022). Evidence review: Sectoral employment programmes and randomised controlled trials.
- Mathematica (2012). Evaluation of Trade Adjustment Assistance. US Department of Labor.
- MDRC. Longitudinal evaluations of transitional jobs programmes.
- Danish active labour market policy evaluations (Aarhus University / national labour market programme evaluations).
Consulting and Industry Reports
- Accenture (2022). AI maturity survey (N≈1,200).
- Accenture (2024). AI maturity and talent strategy survey data.
- ATD (2024). State of the Industry Report. Association for Talent Development.
- Bain & Company. Synchronised workflow and workforce modernisation research.
- BCG. Deploy-Reshape-Invent model for AI transformation.
- BIBB (2022/23). Kosten und Nutzen der betrieblichen Berufsausbildung. Federal Institute for Vocational Education and Training.
- Lightcast (2025). AI skills salary premium data.
- McKinsey & Company. Rewired: The McKinsey Guide to Outcompeting in the Age of Digital and AI.
- MIT Project NANDA (2025). The GenAI Divide: State of AI in Business 2025. (Finding: 95% of organisations saw zero measurable P&L return from generative AI.)
- PwC (2024/2025). Global AI Jobs Barometer.
Historical and Institutional
- JUSE (Union of Japanese Scientists and Engineers). QC Circle documentation and membership records.
- US War Manpower Commission (1940-1945). Training Within Industry programme manuals.
Skills and Competency Frameworks
- CompTIA. AI Essentials, AI Architect+, SecAI+ certification frameworks.
- ESCO (European Skills, Competences, Qualifications and Occupations).
- ILO. Refined Global Index (30,000 task categories).
- Mercer. Deconstruct-Redeploy-Reconstruct framework.
- O*NET (Occupational Information Network).
- SFIA (Skills Framework for the Information Age).
National Workforce Programmes
- France. Compte Personnel de Formation (CPF).
- Germany. Kurzarbeit (short-time work scheme).
- Nordic countries. Flexicurity labour market models.
- Singapore. SkillsFuture, Skills Development Fund (1979), WSQ framework, Institute of Technical Education.
- United States. Trade Adjustment Assistance (TAA).
First draft completed 1 April 2026. Reviewed 2 April 2026; revised 28 June 2026. Status: working draft — canon-consolidated (June 2026). Builds on diagnostic foundations from Whitepaper I (“Sovereign Command”) and Whitepaper II (“The Labour Architecture”). Prescriptive content originally extracted from Whitepaper II on 1 April 2026 and developed into this companion paper.