
Part VIII: The Toolkit — CAGE and ARCH
CAGE (Context, Align, Goals, Examples) sets the AI up; ARCH (Action, Reasoning, Contextual Check, Horizon) verifies every step. Together they form the Logic Pipe — the practitioner toolkit for sovereign AI work.
Part VIII: The Toolkit - CAGE and ARCH
The central crisis of the generative era is not a failure of technology, but a failure of discernment. As established in the preceding chapters, the ease with which Large Language Models (LLMs) produce fluent, authoritative prose creates an Eloquence TrapAI is fluent before it is correct; accepting output because it sounds right. The smoother the output, the more you must verify. Turned inward = mistaking your own fluent confidence for…See full entry → (C4AIL, 2023). This trap lures the uninitiated into granting Epistemic Creditunearned trust granted to fluent AI output by someone who lacks the substrate to verify it; reaching accountability while skipping the knowing.See full entry → to outputs that may be factually hollow or logically incoherent. To move from the role of a passive consumer to that of a Sovereign Orchestrator, the practitioner requires more than a collection of “prompts”. They require a rigorous methodology for Context Engineering.
8.1 - From Strategy to Practice: Context Engineering
In the early stages of the generative revolution, the term “prompting” became the default descriptor for human-AI interaction. However, prompting implies a transactional, almost whimsical relationship - a “poke” to see what the machine produces. For the AI Realist, this is insufficient. We must instead adopt Context Engineering, which is to prompting what structural engineering is to tinkering.
Context Engineering is the deliberate design of the cognitive environment in which an AI operates. It is the process of defining the boundaries, the logic, and the standards of a task before a single token is generated. This is not about restricting the AI’s creative potential, but about providing the scaffolding necessary for high-fidelity output.
A common misconception is that structure stifles creativity. On the contrary, structure is the prerequisite for excellence. Consider the Sonnet Analogy: a sonnet is one of the most restrictive forms of poetry, with a precise rhyme scheme and a strict meter of fourteen lines. Yet, these constraints do not prevent the expression of genius; they provide the tension against which genius is revealed. Similarly, the frameworks of CAGEthe front half of directing AI: Context (all situational/institutional/domain context), Align (the AI plays back its plan before running), Goals (granular, incl. the Must NOT / Must FLAG…See full entry → and ARCHthe agentic verification/execution loop: Action (tiered), Reasoning (captured before output), Contextual Check (authority/compliance/presence pre-commit gate), Horizon (mandatory human…See full entry → provide the “meter and rhyme” for AI-assisted work, ensuring that the model’s probabilistic engine is harnessed toward a specific, verified objective.
That word - harnessed - carries the whole architecture, and it is worth making explicit. ARCH is not a discipline the model performs on itself; it is the control structure of a deterministic harnessthe engineered deterministic 98% you own (gates, autonomy tiers, audit log, kill path); the model is the swappable 2%.See full entry → that runs around the model. The two stages that bite - the Contextual Check and the Horizon - are enforced by that harness, not by the model, for the simple reason that a probabilistic engine cannot be trusted to police itself. This is the 98/2 principle98% deterministic software you own and engineer; 2% swappable model at the edge. Upgrading the model changes neither who is accountable nor where the gate sits.See full entry → operationalised: the harness of gates and hand-offs is the 98% you own and engineer; the model is the swappable 2% you rent. The reliability mathematics below are the why; ARCH’s Contextual Check and Horizon are the deterministic fix.
This is also the correction to the reflex to AI everything. The part that makes an autonomous system work at all is not a cleverer model but the engineered harness around it - a point now demonstrated even in security research, where a deterministic wrapper can carry the safety load while the model itself is assumed compromised. The eagerness to push the model into every gap mistakes the 2% for the 98%; what makes the work survivable is the structure you build around it.




Without this engineering, the practitioner falls into the Reliability Traperrors compound multiplicatively across multi-step / agentic chains (0.95^5 = 77%); each step looks sound alone, so failure is invisible until the end.See full entry →. The mathematics are unforgiving: if each step in a five-step workflow achieves 95% accuracy - impressive in isolation - the cumulative accuracy is 0.95^5 = 77%. One in four outputs will contain at least one error. At ten steps, it drops to 60%. The longer the chain, the more certain the failure. Context Engineering addresses this by improving the per-step accuracy (CAGE) and catching the errors that remain (ARCH), moving the interaction from a narrative chat to a Logic Pipe - a structured, auditable, and repeatable workflow.
8.2 - CAGE: Initialising the AI Environment
The first component of the C4AIL toolkit is the CAGE Framework. CAGE is the initialisation phase of any complex task. It maps the human’s internal expertise onto the AI’s processing environment, providing the knowledge layers the machine cannot generate for itself (see Part II). The five-layer model is best read here as a completeness checklist, not a one-letter-per-layer partition: Context loads all the descriptive context, Goals the deductive intent, Examples the experiential calibration - and Align is not a layer at all, but the step that makes the AI prove it understood before it produces anything.
CAGE stands for Context, Align, Goals, and Examples. When these four elements are defined, the AI ceases to be a generic chatbot and becomes a specialist consultant who has been fully briefed on the mission.
C - Context (All Context)
Context is everything the AI would otherwise have to guess, loaded so it does not have to. It spans the situational layer (the “where” and “when”: domain nuances, the regulatory landscape, the organisation’s market position, temporal urgency) and the institutional layer (how we do things: our tone, quality baselines, hard constraints, the unwritten rules), plus whatever domain facts and data describe the world the task lives in. The two travel together because a real professional brief never separates “here is the situation” from “here is how we handle situations like this”.
Generic AI lacks a “now”. It exists in a flattened sea of training data. By providing Context, the practitioner anchors the model in reality.
- Example: Instead of “Write a report on carbon credits,” the Contextual layer specifies: “We are a mid-sized UK manufacturing firm navigating the 2024 updates to the Carbon Border Adjustment Mechanism (CBAM) for a Tier 1 automotive client.”
- Impact: Good Context turns a generic AI into a specialist consultant briefed on both the engagement and the firm. It matures with the practitioner - the novice loads none; the Orchestrator engineers reusable, retrievable context libraries that become an organisational asset.
A - Align (The Plan-Check)
Align is the dialogic plan-check. Before the AI produces any artefact, you require it to play back two things in plain language: what it understood the task to be, and the specific steps it intends to take. You approve, correct, or redirect - before a single step runs. This is the same commit point that modern agentic architectures (Plan-Act, ReAct) formalise inside the model; Align brings it out to the prompt boundary where a professional can steer it.
The intuition is one every leader already holds: you would never hand a new hire a brief and walk away while they spend two days building the wrong thing. You ask for their understanding and their approach first. Align is exactly that, applied to the super-powered intern - and it is precisely the “plan mode” of modern coding agents. Skip it and the AI charges off confidently in the wrong direction; thirty seconds at Align saves thirty minutes unwinding a polished, wrong artefact.
- Example: “Before you draft anything, tell me what you understand the task to be, what success looks like, and the sequence of steps you’ll take. Wait for my go.”
- Impact: The single highest-leverage letter for non-Orchestrator practitioners - it surfaces a misread as plain sentences you can fix in one round, before any real generation begins. It matures from “letting the AI run” (L0) to a reliable, repeatable gate that makes confident delegation possible (L6).
G - Goals (The Deductive Layer)
The Deductive Layer defines the “what” and “why”. It establishes the success criteria, the specific questions to be answered, and the scope boundaries. Goals live at several granularities at once - the meta-goal (the decision this serves), the success criteria, and the output spec - and you travel between them, zooming up to re-anchor and sharpening down to commit.
Without clear Goals, AI tends toward Scope Creep, adding unnecessary fluff to reach a perceived word count. Goals provide the AI with a “Definition of Done”. They need not arrive fully formed: you can start general and use the AI itself, at the Align step, to sharpen a fuzzy intent into crisp criteria before any work begins.
- Example: “The goal is to identify three specific supply-chain vulnerabilities created by the new regulation. Success is a briefing note that allows a COO to make a ‘go/no-go’ decision on a specific supplier.”
- Impact: This prevents the production of correct answers to the wrong questions.
E - Examples (The Experiential Layer)
The Experiential Layer is the most powerful, yet most often neglected, part of the framework. It provides the AI with reference points for quality, drawn from two directions - internal references (your own prior deliverables and working documents) and external references (standards, published gold-standard work) - and supplied two ways: provided up front, or built iteratively, where the model drafts, you mark “closer” or “wrong”, and that judgement becomes the next calibrating example.
AI models are pattern-matchers. By providing Few-Shot Examples of what “good” looks like - and, crucially, what “bad” looks like - you calibrate the model’s internal quality filter. Crucially, Examples is not a slot you fill once: every working document you keep becomes a future Example, so this layer grows with every task - the seed of the organisation’s Knowledge Layerthe codified expert-knowledge specifications an Architect builds (operationally, the Institutional Vault); lets a task reduce from a paragraph of context to one sentence.See full entry → (Part IX) and its retrieval capability.
- Example: “Attached is last year’s successful briefing (Good). Also attached is a rejected draft that was too academic and lacked actionable data (Bad).”
- Impact: This provides YOUR definition of quality, not the internet’s average. It eliminates the Effort Gradient where the AI takes the path of least resistance.


The Compound Effect
CAGE components are not independent - they compound. Context without Align produces output that may be working from the right knowledge but a misread of the task. Goals without Context produces output that knows what success looks like but not where you are starting from. Examples without Goals produces output that looks like previous work but may not serve the current purpose. All four together produce output that is contextually grounded, plan-verified before execution, strategically targeted, and calibrated to professional quality standards. This is what separates context engineering from prompting. A prompt provides one or two of these. CAGE provides all four, systematically, with Align closing the loop before any artefact is committed.
8.3 - ARCH: The Verification Chain
If CAGE is the setup, ARCH is the execution. One of the primary failures in AI adoption is the “One-Shot Fallacy” - the belief that a complex task can be completed in a single prompt. In reality, high-stakes work requires a multi-step process.
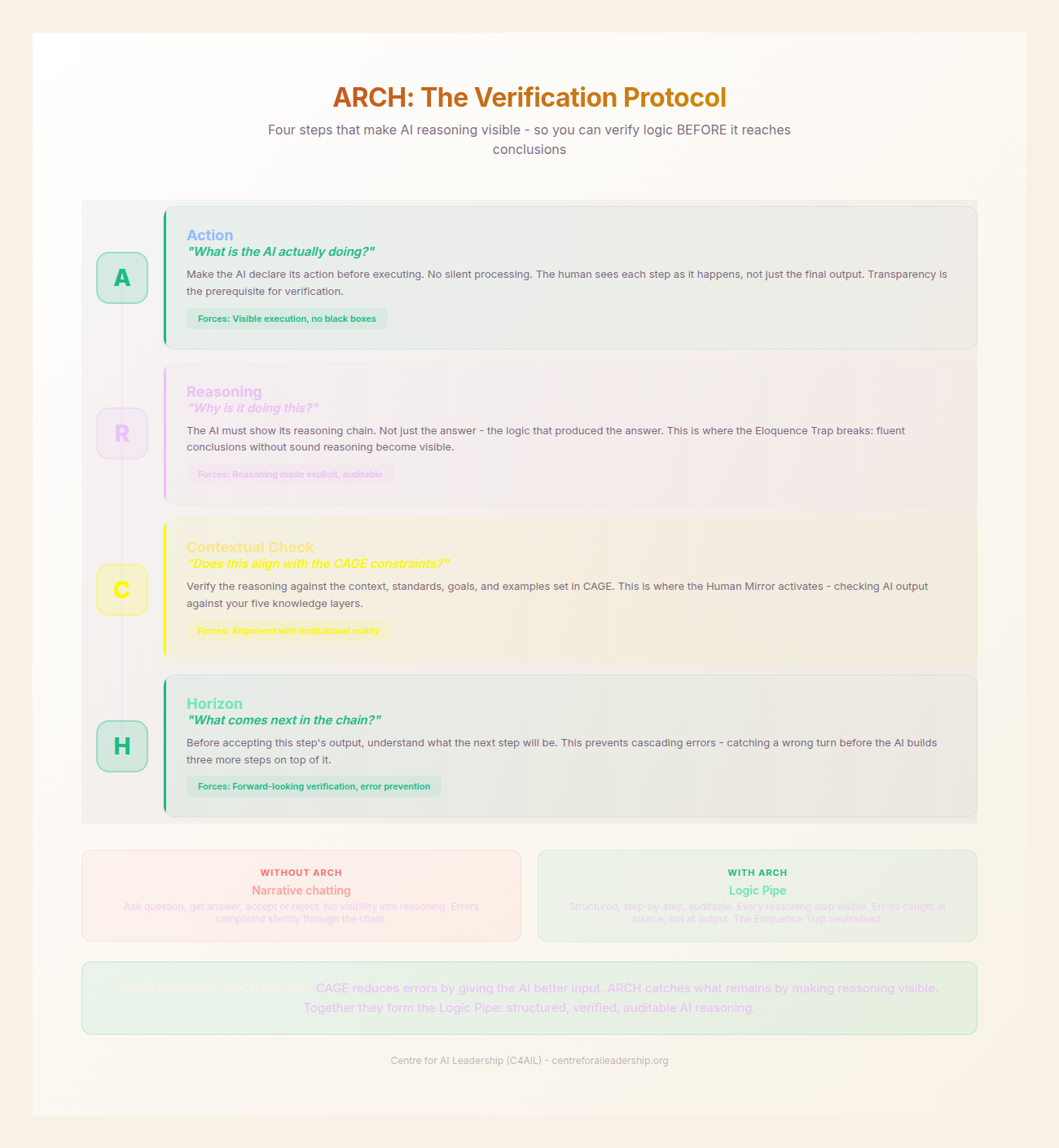
ARCH is a cycle that must be applied at every discrete step of a task. It stands for Action, Reasoning, Contextual Check, and Horizon. By forcing the AI to cycle through these four stages, the practitioner maintains Sovereign Commandthe state where an org owns its AI-informed decisions, can defend them, and can scale them without losing control; human judgment kept above machine fluency. The outcome ARGS produces. "Not…See full entry → over the logic, not just the output.
A - Action
The Action defines the specific, verifiable task for the current step. It must be granular. Instead of “Write the report,” the Action might be “Outline the three primary regulatory hurdles based on the provided PDF.” An Action can be a single discrete move or the invocation of a named, reusable procedure - an algorithm; the grain rises with maturity, and it helps to type each Action (retrieve, transform, evaluate, generate, decide).
- Requirement: The task must be small enough that the human can verify it in under sixty seconds.
R - Reasoning
This is the most critical intervention for breaking the Eloquence Trap. Before the AI produces the final output for a step, it must be commanded to explain its logic.
Visible Reasoning allows the practitioner to see if the AI is “thinking” correctly. The deepest check is on the orientation - is this step goal-oriented (converging on a known target) or discovery-oriented (exploring what is not yet known)? - because a confident march toward the wrong target is the most dangerous failure. If the reasoning is flawed, the output will be flawed, regardless of how well-written it appears.
- Requirement: “Explain your logic for selecting these three hurdles before you write the summary.”
- Impact: When reasoning is visible, verification becomes possible.
C - Contextual Check
The Contextual Check is a feedback loop back to the CAGE framework, and it runs on two axes. The first is presence: is the CAGE block still in the window? In a long chat or a long agentic run, the constraints set at initialisation can literally scroll out of view or fall victim to lost-in-the-middle attention degradation, so the first move is to confirm they are still present - and re-inject a compact restatement if they are not. The second is compliance, which addresses a failure mode CAGE alone cannot prevent: mid-chain drift. In long-form AI interactions, models maintain internal coherence - the output continues to sound right - while gradually departing from the CAGE constraints established at initialisation. The tone shifts from your institutional standard to the AI’s default register. The analysis pursues an interesting tangent that no longer serves the decision-maker’s actual question. The quality drops from the calibrated standard to the AI’s generic output level. This is the Eloquence Trap applied to workflow chains: the output gets more eloquent and less accurate as the chain progresses.
The Contextual Check asks: “Is the context still here, and does this step still respect our initial Context, Align, Goals, and Examples?”
- Requirement: A targeted compliance check at each step - not a full re-read of the CAGE, but a specific verification that this step’s approach respects the constraints. Step 3 might check “Am I still evaluating against our risk framework, not generic best practice?” while Step 5 might check “Is this recommendation within the air-gapped constraint?”
H - Horizon
The Horizon prevents premature resolution. It asks the AI to state what the next step is before concluding the current one. Stated precisely, Horizon is the hand-off contract - “this step produces X, which the next step consumes as Y” - and it is what chains one Action into the next; when Actions are algorithmic, Horizon is what composes a set of named procedures into a single pipeline. This maintains Chain Coherence and ensures that the logic of Step 1 flows seamlessly into Step 2.
- Requirement: “What is the next logical step to complete the Goal defined in CAGE?”
ARCH is not a checklist to be ticked off once; it is a Verification Cycle. Step 1: A→R→C→H → Human review point Step 2: A→R→C→H → Human review point
Not every step needs a full human review - Part V’s content tiering (Queue Aroute AI output by confidence: A auto-approved + logged, B Translator-reviewed, C escalated to Architect/Orchestrator.See full entry →/B/C) applies here. Routine steps get automated checks. Complex steps get domain expert review. High-stakes steps get full Orchestrator verification. But the ARCH structure is present at every step, creating the visibility that makes triage possible. You cannot route to the right reviewer if you cannot see what the step is doing. ARCH creates that visibility.
This iterative process ensures that the human remains the “judge” at every junction. It transforms the AI from a black box into a transparent Logic Pipe.
ARCH is also the human-legible form of the agentic loop itself. Its four steps map onto the loop that modern agentic architectures (ReAct, Plan-Act) run inside the model - Reasoning is the “thought”, Action the “act”, Contextual Check the “observation” re-grounded against the plan, Horizon the next-step planning. (The letters are a mnemonic, not the run order: in execution the AI reasons before it acts - ReAct’s thought→act - so Action names the step Reasoning has just justified, before the output commits.) The industry built this loop from the technical side; ARCH renders the same structure so a professional can run it by hand, without reading the model’s internals. Because composition is recursive, it holds at every node of a multi-step agentic process - which is why the same protocol governs a quick chat and a long autonomous run.

8.4 - CAGE + ARCH = The Logic Pipe
When we combine CAGE and ARCH, we create a Logic Pipe. This is a structured, verified, and auditable chain of thought that leads to a high-fidelity deliverable.
To understand the power of a Logic Pipe, we must contrast it with Narrative Chatting. In a narrative chat, the user asks a question, the AI provides an answer, and the user either accepts it or asks for a “tweak”. This is a low-leverage activity because the logic remains hidden. The user is judging the “veneer” of the output, not the “engine” of the thought.
In a Logic Pipe, the process is inverted:
- Initialisation: The CAGE framework sets the parameters.
- Modular Execution: The task is broken into ARCH cycles.
- Human Interdiction: The human reviews the Reasoning at each step.
- Verification: The final output is the result of a series of verified logical steps.
The Reality of Hallucination
We must be clear-eyed about the nature of the technology. AI models do not “retrieve” facts; they predict the next most likely token based on a probabilistic map. Consequently, Hallucination is not a bug that can be patched out; it is an inherent feature of the architecture.
Even with perfect context, AI can suffer from Fusion Errors (combining two unrelated facts), Positional Bias (favouring information at the start or end of a prompt), and Reasoning Failures.
The CAGE/ARCH toolkit is designed for a reality where AI hallucinates.
- CAGE eliminates ignorance-based hallucinations by providing the necessary facts and constraints.
- ARCH catches logic-based hallucinations by making the “thinking” visible.
- Human Agency catches what ARCH misses.


A Logic Pipe is a system designed to produce truth from a probabilistic machine. It is the practical application of the Human Mirror concept (see Part III) - using the AI to reflect and refine human intent, rather than replacing it.
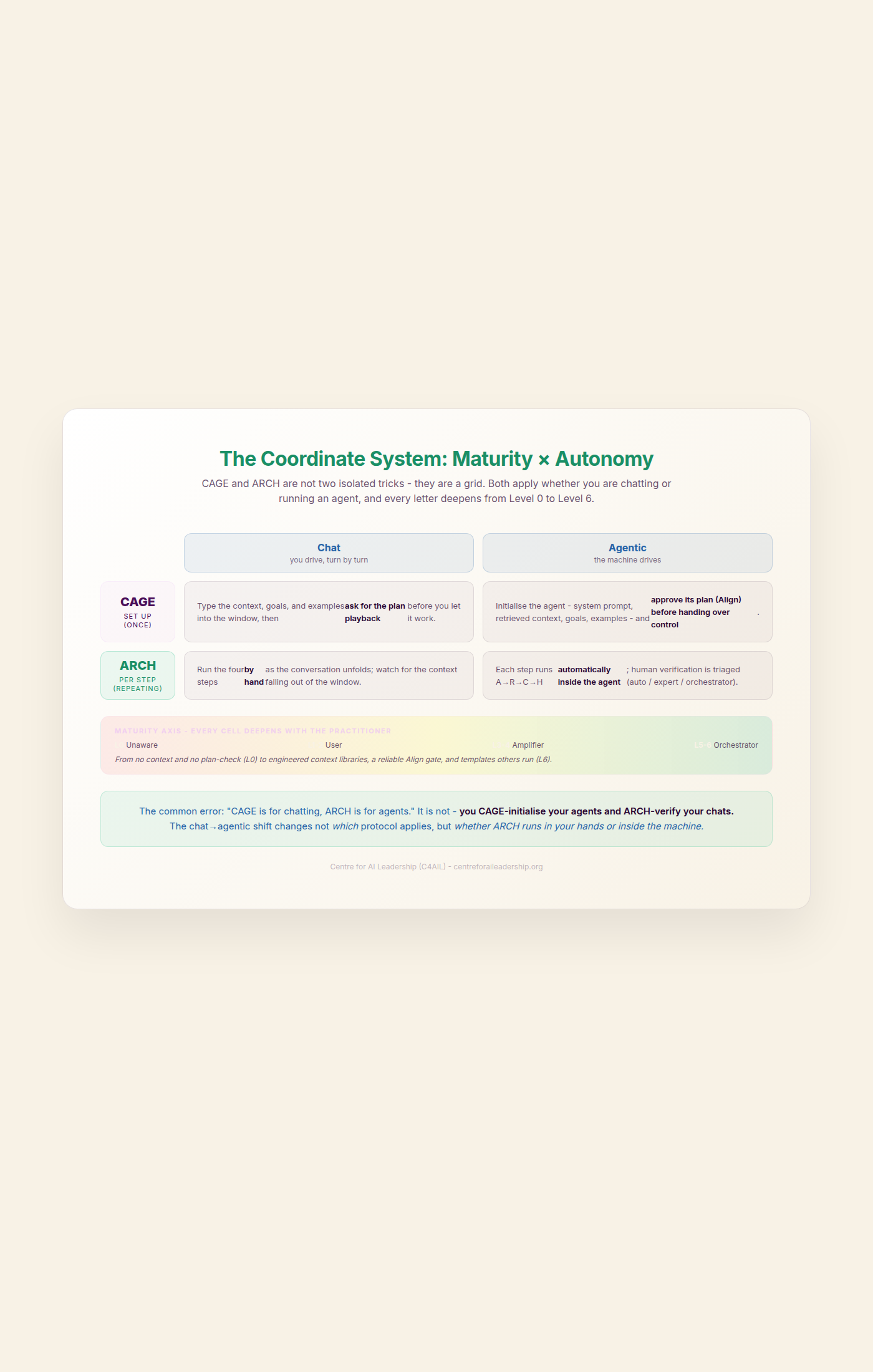
Two final properties make the Logic Pipe more than a checklist. First, it is a flywheel: every verified ARCH output is a new reference, and references are exactly what CAGE-Examples accumulates, so today’s audited output becomes tomorrow’s Example. The data layer grows and the next initialisation is richer; for recurring tasks the next chain even runs shorter, as accumulated Examples short-circuit steps it would otherwise re-derive - the same compounding the Knowledge Layer treats in full in Part IX. Second, CAGE and ARCH form a coordinate system rather than two isolated tricks: every letter matures from Level 0 to Level 6, and the whole toolkit applies whether you are chatting or running an agent. These axes are orthogonal - you CAGE-initialise your agents and ARCH-verify your chats. What the shift from chat to agentic changes is not which protocol applies, but whether ARCH runs in your hands or inside the machine.



8.5 - The Infrastructure Prerequisite
To deploy CAGE and ARCH effectively at an organisational level, certain Infrastructure Prerequisites must be met. These are the foundational elements that allow Context Engineering to scale from an individual skill to a corporate capability.
1. Model Selection
Not all models are created equal. A Logic Pipe requires a model with high Reasoning Density. While smaller, faster models might be suitable for simple summarisation, complex Context Engineering requires top-tier reasoning models that can maintain long-context coherence and follow multi-step instructions without drifting. The CAGE/ARCH process makes these requirements visible, allowing for more rational model selection.
2. Context Engineering and RAG
While CAGE provides the manual context, Retrieval-Augmented Generationgrounding output in retrieved source documents (with citations) to reduce hallucination; a core GenAI architecture fix.See full entry → (RAG) provides the automated context. However, RAG is often implemented poorly as a “search” tool. In a Sovereign Command environment, RAG must follow from CAGE requirements. The data being retrieved must be curated to fit the Institutional and Experiential layers of the framework.
3. Cost Planning
Context Engineering is token-intensive. Forcing an AI to “Reason” before it “Acts” doubles or triples the token consumption for a given task. However, this is a Value-Positive Trade-off. The cost of a few thousand extra tokens is negligible compared to the cost of a human expert spending hours fixing a hallucinated or poorly aligned output. CAGE and ARCH allow for transparent cost planning by making the “Logic Pipe” visible and measurable.
4. Template Libraries
In a mature AI-enabled organisation, CAGE and ARCH frameworks are not recreated from scratch for every task. They are maintained as Template Librariesversioned repositories of validated reasoning chains (structure + constraints + quality bar + known failure modes).See full entry → - living organisational assets that encode the “Gold Standard” for various workstreams.
- An “Investment Memo CAGE”
- A “Technical Specification ARCH”
- A “Crisis Communication Logic Pipe”


These templates are the modern equivalent of the “Standard Operating Procedure”, but instead of being static documents in a graveyard, they are active “engines” that experts use to accelerate their work.
A Historical Warning
We must learn from the failures of the past. In the 1980s, the world was promised a revolution through Expert Systems. These systems tried to encode human expertise into a series of “if-then” rules, effectively trying to remove the expert from the loop. They failed because they were brittle and could not handle the complexity of the real world.
In the 2000s, Knowledge Management (KM) promised to capture expertise in vast document repositories. These became “graveyards of wisdom” because they were passive and disconnected from the actual flow of work.
CAGE and ARCH must not repeat these mistakes. They are not intended to replace the expert, but to provide an Expert Extension. The human must remain at every judgment point. The framework provides the “Sovereign” with a more powerful “Command” over the machine, but the responsibility for the final output remains, as it always must, with the human.
Practical Example: This Whitepaper
To demonstrate the efficacy of these tools, it should be noted that this paper was produced using CAGE and ARCH.
- CAGE Initialisation: The “Context” was defined as a whitepaper for senior leadership in the C4AIL house style (British English, hyphens only, evidence-dense); “Align” required a plan-back of each part’s structure and approach before drafting; the “Goal” was to provide actionable frameworks; the “Examples” were previous C4AIL high-authority publications.
- ARCH Execution: Each section was drafted in cycles. For Part VIII, the “Action” was to detail the toolkit; the “Reasoning” phase identified the need to contrast “chatting” with “engineering”; the “Contextual Check” ensured no em-dashes were used; the “Horizon” pointed toward the Knowledge Layer in Part IX and the implementation strategies in Part X.
The result is a document that is not a generic “AI-generated” summary, but a precise, high-fidelity instrument of leadership. This is the power of the Logic Pipe. This is the path to Sovereign Command.