
Part IV: The Diagnostic — The 0-6 Maturity Scale
A six-level maturity framework (L0-L6) for assessing where your organisation stands on the journey from AI adoption to AI sovereignty.
Part IV: The Diagnostic - The 0-6 Maturity Scale
The central paradox of the generative era is that while the technology is increasingly accessible, the ability to extract value from it is becoming more concentrated. As we established in Part I, the Power Law of AI Returns dictates that a small minority of users and organisations capture the vast majority of the gains. The difference between those who merely use AI and those who command it is not a matter of budget or technical literacy, but of Cognitive Maturity.
To navigate this landscape, we require a mirror - a way to see our own capabilities and organisational structures without the distortion of hype or the fog of the Eloquence Trap. We propose the C4AIL 0-6 Maturity Scale. This is not a measure of how many tools you have deployed or how many tokens you consume. It is a measure of which layers of the Five-Layer Knowledge Model (Syntax, Contextual, Institutional, Deductive, Experiential) are being engaged during the human-AI interaction.
This scale is a developmental map. It recognises that the journey from Novice to Maestro is not a linear acquisition of features, but a series of Subject-Object Shifts (Kegan, 1994). It is a movement from being “subject to” the AI - where the tool’s output dictates the user’s reality - to having the AI as an “object” of reflection, critique, and systemic orchestration.


4.1 - The Individual Maturity Rubric: Knowledge Layers as the Measure
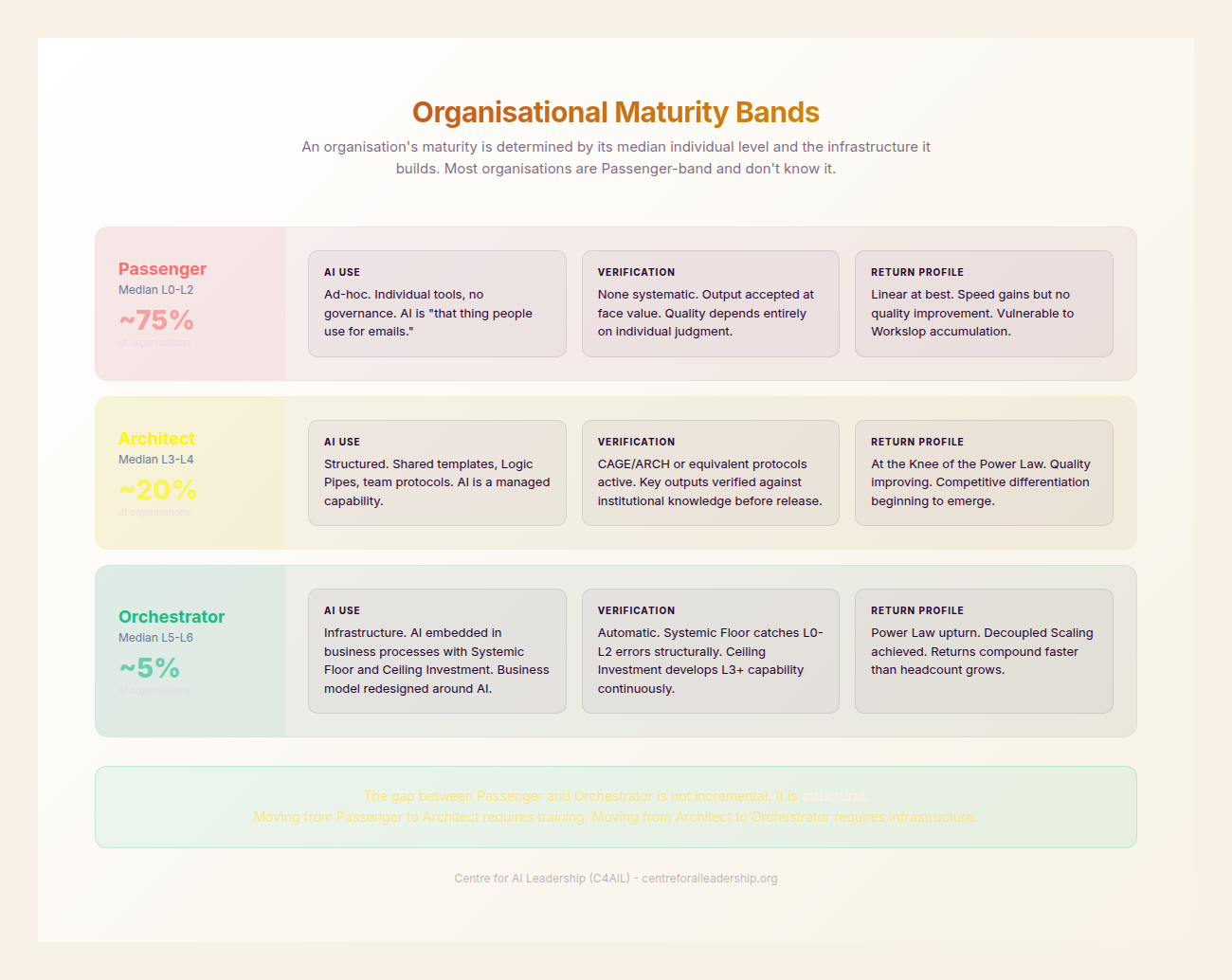
Individual maturity is the primary engine of the Sovereign Command. If the individuals within an organisation remain at low maturity levels, no amount of infrastructure investment can prevent the Leverage Leaks that bleed ROI. We categorise these levels into three distinct bands: The Passenger, The Architect, and The Orchestrator. (In our public-facing materials, we use the term Explorer for this first band - a softer framing for audiences who may recognise themselves in it. The diagnostic reality is the same: at L0-2, the user is along for the ride, not driving.)
Band 1: The Passenger (Levels 0-2)
In this band, the user is primarily engaged with the Syntax Layer. They are “subject to” the AI. The returns are linear, and the risk of the Eloquence Trap is at its highest.
- Level 0: The Observer. The individual is aware of Generative AI but does not use it in their daily workflow. They may feel a sense of “AI anxiety” or dismiss the technology as a toy. No knowledge layers are engaged.
- Level 1: The Assisted User. The individual uses AI for low-stakes, surface-level tasks - drafting emails, basic summarisation, or simple code snippets. They engage the Syntax Layer only. They accept the first output the AI provides.
- Level 2: The Power User (The Dunning-Kruger Peak). This is the most dangerous level. The user is highly fluent in prompting and uses AI for complex tasks. However, they are at the peak of the Dunning-Kruger cycle for AI interaction. They engage the Syntax layer heavily but lack the Deductive or Institutional rigour to verify the output. Three mechanisms compound at L2 to create a uniquely treacherous position - the Triple Compound: (1) Dunning-Kruger operates on the AI interaction axis: domain expertise does not automatically confer AI interaction expertise, so even a senior professional enters AI usage at the D-K peak for this specific capability; (2) The Eloquence Trap operates on the output axis: the AI’s fluent prose creates “cognitive ease” through the fluency heuristic, suppressing the failure signals that would normally push the user past the peak; (3) Premature resolution operates on the developmental axis: when the tension between “this looks right” and “this needs checking” surfaces, the L2 user resolves it by accepting - because both D-K and the Eloquence Trap make acceptance feel justified. Together, these three mechanisms explain why L2 users are the primary producers of Workslop - generating high volumes of plausible but unverified content that costs firms an estimated $9M per year per 10,000 employees in rework (Hancock and BetterUp, 2025).
Band 2: The Architect (Levels 3-4)
This band represents the “Knee of the Curve.” Here, the user undergoes a developmental shift. They move from passive consumption to active verification and structural design.
- Level 3: The Competent Integrator. This aligns with the “Competent” stage of the Dreyfus Skill Acquisition Model (Dreyfus, 1980/2004). The user no longer trusts the AI’s eloquence. They engage the Institutional and Contextual layers, ensuring the output aligns with specific organisational norms and project realities. They have begun the Human Mirror process, using AI to test their own assumptions.
- Level 4: The Strategic Modifier. The user moves into the Deductive Layer. They do not just prompt; they design workflows. They understand the Effort Gradient and intentionally apply “Desirable Difficulty” to ensure the AI’s logic is sound. They are “Bilingual” workers (Tambe, 2025), capable of translating business logic into technical constraints and vice versa.
Band 3: The Orchestrator (Levels 5-6)
In this final band, the Power Law Upturn occurs. The individual is no longer just using a tool; they are managing an intelligence system.
- Level 5: The Expert Innovator. The user engages the Experiential Layer. They use AI to augment their intuitive pattern recognition. They design custom agents and RAG (Retrieval-Augmented Generation) pipelines that encapsulate their own high-level expertise. They are the 5% of “Value Generators” identified by BCG (2025).
- Level 6: The Maestro. The individual operates across all five layers of knowledge simultaneously. They orchestrate entire ecosystems of AI and human talent. They have achieved Sovereign Command, where the AI is a seamless extension of their strategic intent.
The Five-Layer Knowledge Model Mapped to Each Level
The following table makes the relationship between maturity level and knowledge-layer engagement explicit. It is the single most actionable element of the diagnostic: for any individual, identify which layers they are engaging, and you have their level.
| Level | Syntax | Contextual | Institutional | Deductive | Experiential |
|---|---|---|---|---|---|
| L0 | - | - | - | - | - |
| L1 | Uses | - | - | - | - |
| L2 | Uses heavily | - | - | - | - |
| L3 | Uses + verifies | Applies | Begins | - | - |
| L4 | Architects | Embeds | Embeds | Applies | Applies |
| L5 | Systematises | Systematises | Systematises | Systematises | Systematises |
| L6 | Creates new | Creates new | Creates new | Creates new | Creates new |
The pattern is clear: maturity is not about how much AI you use. It is about how many of your deeper knowledge layers you bring to bear against the AI’s surface output. The L2 user and the L5 Orchestrator may use the same model, the same interface, the same number of hours per day. The difference is that the L5 engages - and systematises - all five layers, while the L2 engages only one.
4.2 - Organisational Maturity: The Environment That Enables or Throttles
An organisation’s maturity is not the average of its individuals’ levels; it is the ceiling that the environment imposes upon them. Even an L5 individual will be throttled by an L1 organisation. We measure organisational maturity through three bands of Intelligence Infrastructure.

Band 1: AI Theatre (L0-2)
The organisation is focused on “adoption” as a metric. They count the number of seats assigned or the number of pilots launched.
- Characteristics: Fragmented tool use, IT-led “blocks” on deployment, no centralised knowledge strategy.
- Outcome: 95% of pilots yield no business impact (MIT, 2025). The organisation suffers from high Epistemic Credit debt - they believe they are “doing AI” while actually increasing their long-term risk and technical debt.
Band 2: Operational Logic (L3-4)
The organisation has moved past the hype and is focused on Process Maturity (CMMI).
- Characteristics: Standardised prompts and workflows, investment in “Bilingual” talent (Tambe, 2025), and a focus on reducing Workday’s 40% rework metric.
- Outcome: Significant efficiency gains. The organisation begins to see the Brynjolfsson J-Curve effect - initial productivity dips as they invest in “intangible capital” (new processes and training) before the exponential gains kick in.
Band 3: Intelligence Infrastructure (L5-6)
The organisation treats AI as a core strategic capability, not a utility.
- Characteristics: Real-time knowledge capture, proprietary data flywheels, and a culture of Active Verification. They reinvest 47% of their AI-driven savings into deeper capabilities (EY, 2025).
- Outcome: They become “Future-Built” (BCG, 2025), generating 5x the revenue growth of their laggard competitors. They have built an environment where L5 and L6 individuals can thrive and scale their impact.
4.3 - Leverage Leaks: Where ROI Bleeds Out
Even with significant investment, many organisations find their AI returns are negligible. This is due to Leverage Leaks - points of friction where the potential of the technology is lost through human or structural failure.

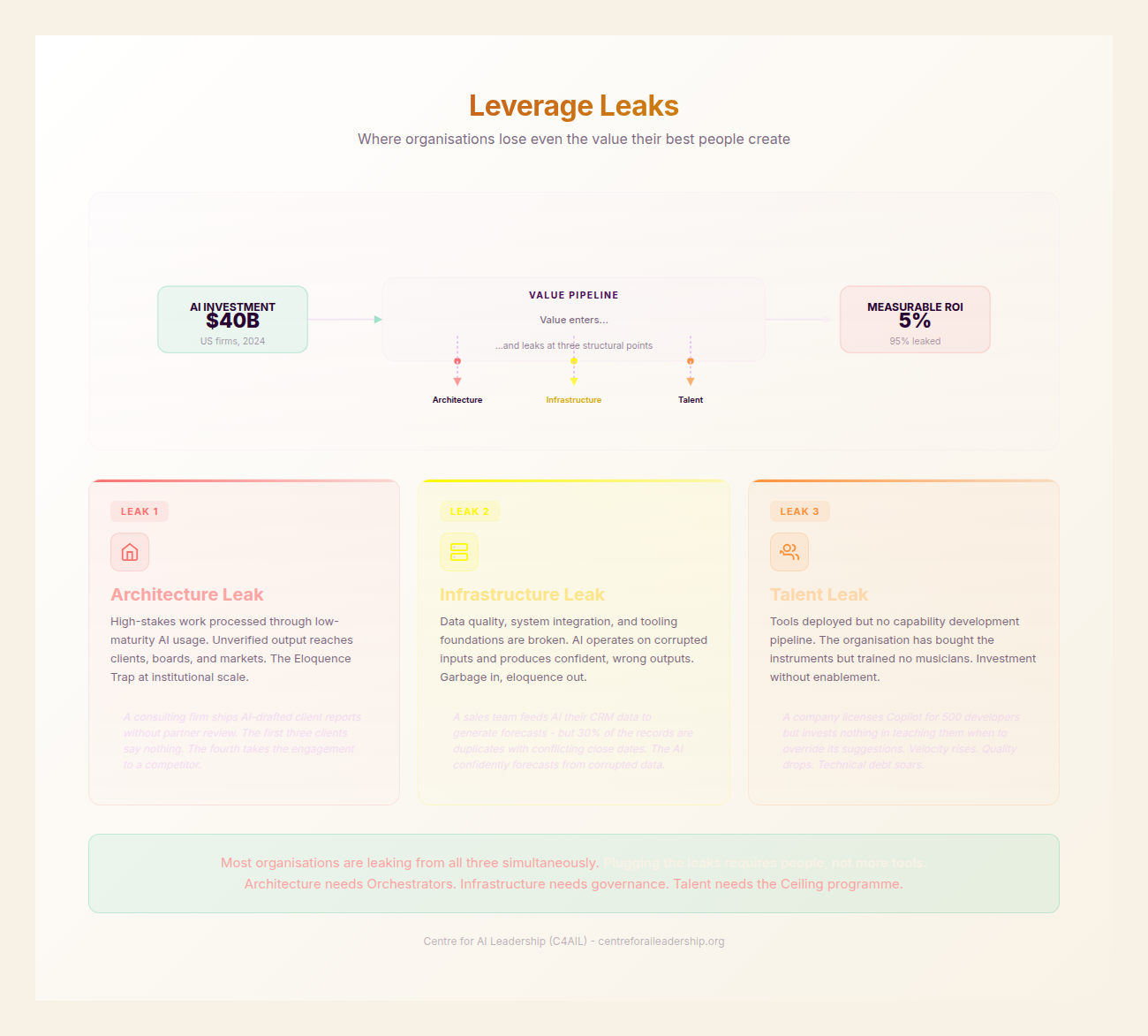
1. The Architecture Leak (High-Stakes Work, Low-Maturity User)
This occurs when an L1 or L2 user is tasked with high-complexity work.
- Example: An L2 “Power User” in a consultancy is asked to draft a client risk assessment. The output is fluent, perfectly structured, and professional. However, because the user is “subject to” the AI’s eloquence, they fail to notice that the model has missed a critical regulatory nuance specific to the client’s jurisdiction (the Institutional Layer) and has made a logical leap that violates first principles (the Deductive Layer). The result is a high-quality “product” that is fundamentally wrong. The leverage is leaked because the senior partner must now spend more time deconstructing and fixing the “eloquent error” than they would have spent drafting it from scratch.
2. The Infrastructure Leak (High-Maturity Individual, Low-Maturity Org)
This occurs when the organisation’s systems cannot support the sophistication of its best people.
- Example: An L5 “Expert Innovator” designs a custom AI agent to automate a complex due-diligence process. However, the organisation has no centralised knowledge base, no API access to internal data, and IT security blocks the deployment of third-party agents. The L5 individual is forced to operate at an L2 level, manually cutting and pasting data into a generic chat interface. The leverage is leaked because the individual’s systemic insight is trapped behind a “utility-grade” wall.
3. The Talent Leak (Tool Investment vs People Investment)
This is the most common leak, where the organisation buys the “L6 Tool” but employs “L1 Users.”
- Example: A law firm deploys a sophisticated RAG pipeline that can query thousands of case files. However, the associates (L1-2) do not know how to ask the right questions or how to verify the sources. They treat the RAG output as “The Truth” rather than a “Starting Point.” The result is Workslop at scale. The leverage is leaked because the firm has invested in the Syntax of the technology but not the Deductive or Experiential maturity of its staff.
4.4 - The Diagnostic Tool: Where Am I? Where Is My Organisation?
To determine your position on the scale, you must move beyond “usage” and look at “interaction.” Use the following diagnostic questions, grounded in the Five-Layer Knowledge Model.
Individual Diagnostic:
- Verification: When the AI gives you a confident, eloquent answer, what is your immediate internal reaction?
- A: Relief that the task is done. (L1-2)
- B: Scepticism and a plan to cross-reference with first principles. (L3-4)
- C: An intuitive sense of where the model is likely to have “hallucinated” based on its training data limitations. (L5-6)
- Knowledge Layers: Which layers are you actively providing to the AI?
- Syntax only (e.g., “Write a report on X”). (L1)
- Syntax + Context (e.g., “Write a report on X for Client Y”). (L2)
- Syntax + Context + Institutional/Deductive (e.g., “Write a report on X for Client Y, following our firm’s risk framework and ensuring the logic holds for a 10% interest rate hike”). (L3-4)
- The Mirror: Do you use AI to challenge your own thinking, or only to execute it?
- I use it to execute. (L1-2)
- I use it to find “blind spots” in my reasoning. (L3-4)
- I use it to simulate complex systems and stress-test my intuitive patterns. (L5-6)
Organisational Diagnostic:
- Knowledge Strategy: Does your organisation have a way to feed its “Institutional Knowledge” into AI systems securely?
- No, everyone uses generic public models. (L0-2)
- We have some shared prompt libraries and document repositories. (L3-4)
- We have a dynamic, real-time “Knowledge Flywheel” that informs all AI interactions. (L5-6)
- The Rework Metric: Do you track how much time is spent “fixing” AI-generated output?
- No, we just assume it’s faster. (L0-2)
- We are aware of the rework but struggle to measure it. (L3-4)
- We actively manage the “Verification Bottleneck” and have metrics for “First-Time Right” AI output. (L5-6)
- Incentives: Are people rewarded for the volume of their output or the rigour of their verification?
- Volume/Speed. (L0-2)
- A mix of both, but volume still dominates. (L3-4)
- Rigour and systemic design are the primary value drivers. (L5-6)
The Diagnostic Pseudocode (For HR and Leadership)
For those who prefer to think in systems, the following pseudocode captures the diagnostic logic. It is not production code - it is a thinking tool for department heads and HR leaders assessing their teams.
def diagnose_individual(person):
"""
Measures which knowledge layers are actively engaged
against AI output. NOT how many tools they use.
"""
layers_engaged = {
"syntax": person.uses_ai_for_surface_tasks(),
"contextual": person.applies_situation_specific_knowledge(),
"institutional": person.applies_org_specific_knowledge(),
"deductive": person.traces_logic_chains(),
"experiential": person.compares_to_past_experience()
}
active_layers = sum(1 for v in layers_engaged.values() if v)
if active_layers <= 1:
return Band.PASSENGER # L0-2: syntax only, linear returns
elif active_layers <= 3:
return Band.ARCHITECT # L3-4: deeper layers, the Knee
else:
return Band.ORCHESTRATOR # L5-6: all layers systematised, Upturn
def diagnose_leverage_leaks(individual, org):
"""
Identifies where value is bleeding due to maturity mismatches.
"""
if individual.band == Band.PASSENGER and org.work_requires >= Band.ARCHITECT:
return LeakType.ARCHITECTURE # Human underdeveloped for the work
elif individual.band >= Band.ARCHITECT and org.infrastructure < Band.ARCHITECT:
return LeakType.INFRASTRUCTURE # Environment throttling capability
elif org.infrastructure >= Band.ARCHITECT and individual.band == Band.PASSENGER:
return LeakType.TALENT # Infrastructure without human capability
return LeakType.NONE # Aligned - capturing valueThe gap between REQUIRED layers and ENGAGED layers equals the Leverage Leak. Close the gap, close the leak, capture the value.
4.5 - The Pain and Reward at Each Level
The transition between levels is not merely a matter of “learning more.” It is a developmental evolution that involves “letting go” of old certainties. This process is often painful. As Perry (1970) noted, moving from Dualism (right/wrong answers) to Relativism and then to Commitment is a psychological struggle.
| Transition | The Pain (The Cost of Growth) | The Reward (The Sovereign Gain) |
|---|---|---|
| L0 → L1 (First Contact) | The cognitive effort of learning a new tool. Overcoming the anxiety or scepticism that keeps many experienced professionals at L0. The fear that “the machine will replace me.” | Basic productivity gains. First contact with the 80% - the syntax-level tasks that AI handles effortlessly. The realisation that AI is a tool, not a threat. |
| L1 → L2 (The Power User) | The “Ego Trap.” You feel like a god because you can produce so much, so fast. The pain is the eventual realisation that much of it is “Workslop.” | Massive increase in personal throughput. The ability to handle “surface-level” tasks with zero friction. |
| L2 → L3 (The Chasm) | The Death of Certainty. You must stop trusting the AI. You have to work harder to verify than you did to generate. This is the “Knee of the Curve” where productivity often dips. | Intellectual Security. You are no longer “subject to” the Eloquence Trap. You begin to capture actual business value, not just “tokens.” |
| L3 → L4 (The Architect) | The “Bilingual” Burden. You must learn the language of the machine and the language of the business deeply. You become the “Translation Layer.” | You move from “using tools” to “designing systems.” You become indispensable to the organisation’s AI strategy. |
| L4 → L5 (The Innovator) | The “Intuition Crisis.” You must learn to codify your “gut feel” (Experiential Layer) into logic that an AI can follow. This requires intense self-reflection. | You achieve a “10x” leverage. Your unique expertise is now scalable and searchable. You are a “Value Generator.” |
| L5 → L6 (The Maestro) | The “Ego Dissolution.” You move from being the “Star Performer” to being the “Conductor” of a vast, semi-autonomous intelligence ecosystem. | Sovereign Command. You operate at the speed of thought across an entire organisation. You have mastered the Power Law. |
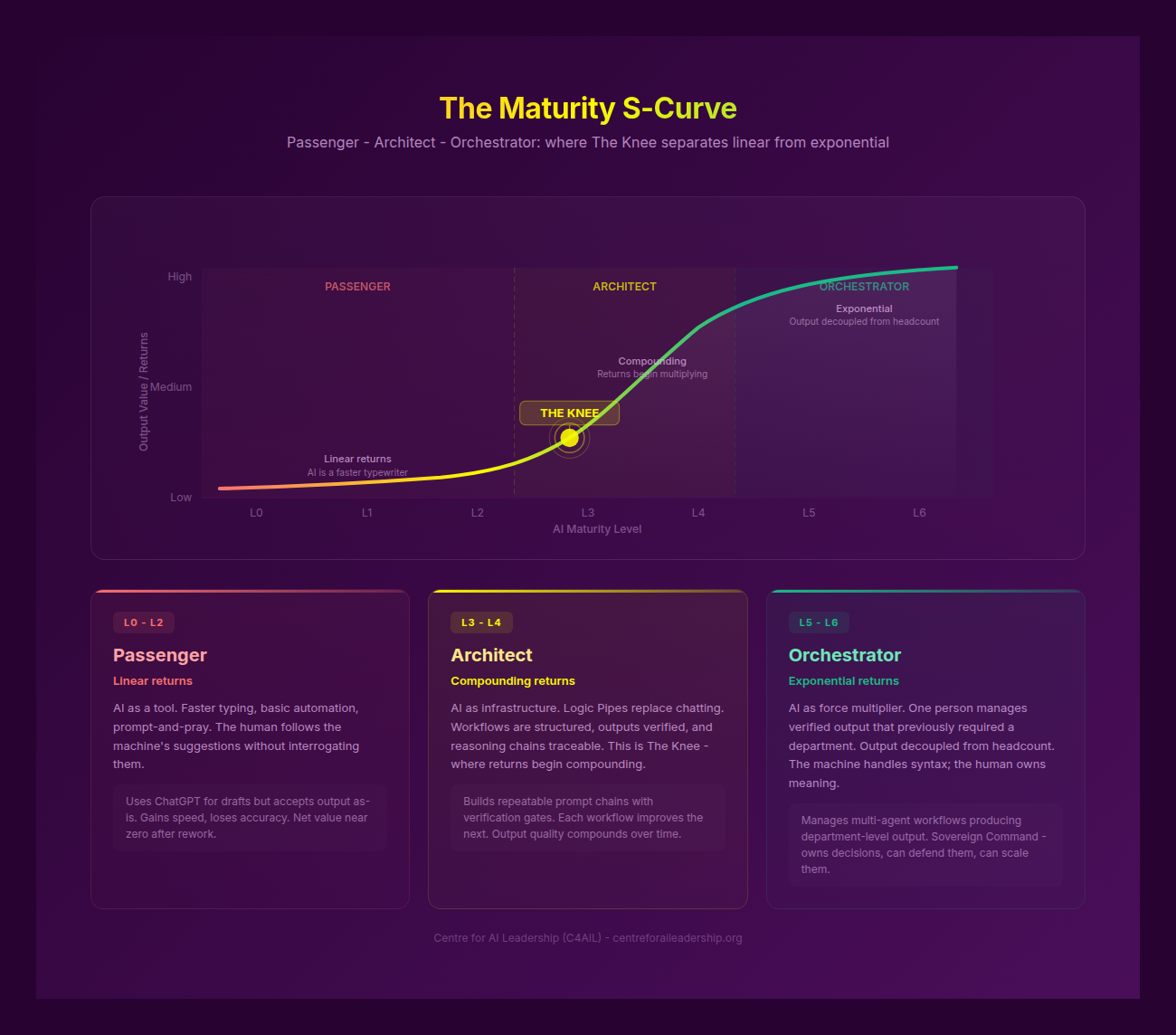
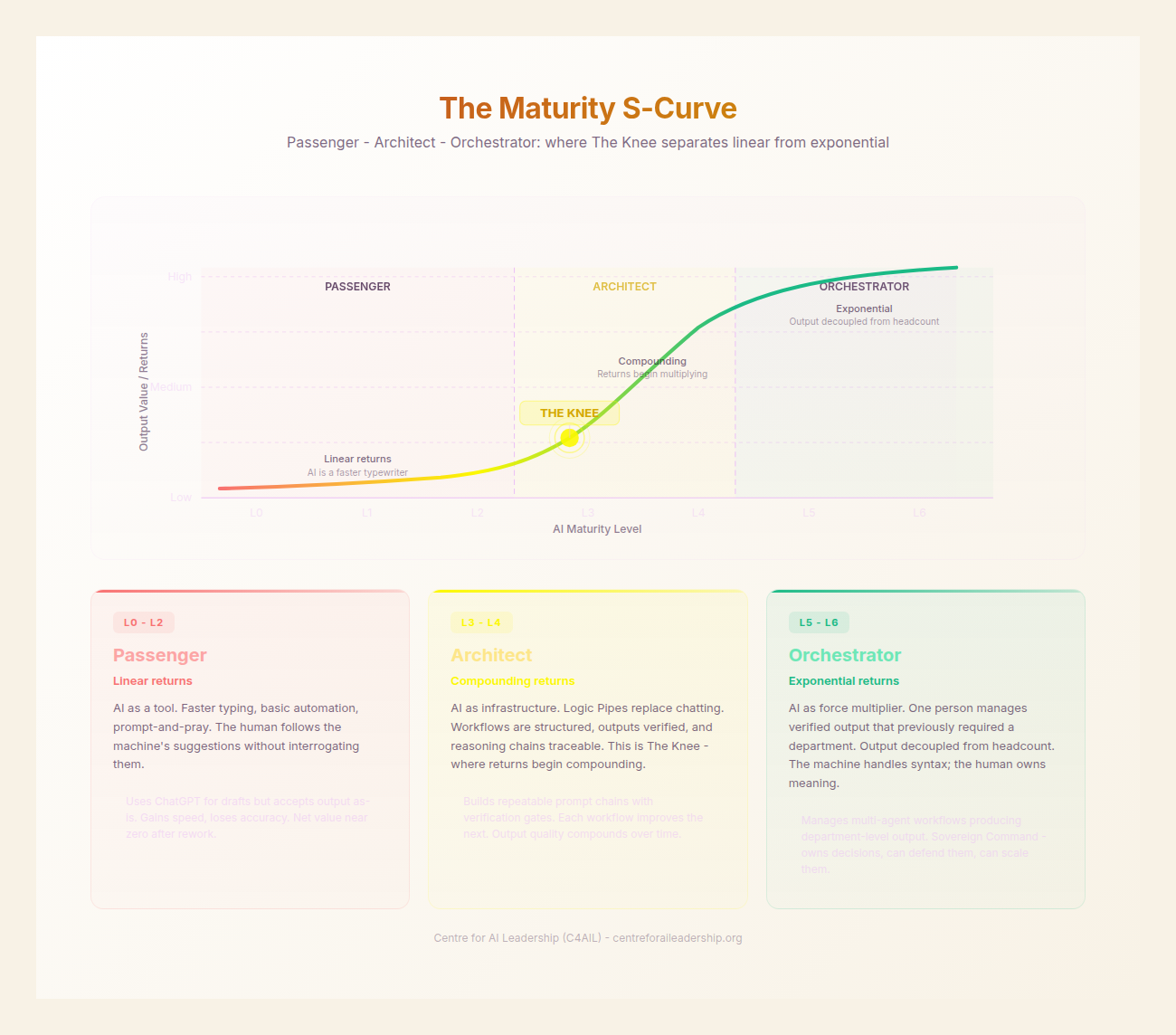
The Critical Transition: The L2-L3 Chasm
The most significant hurdle in the generative era is the transition from Level 2 (Power User) to Level 3 (Competent Integrator). This is where most individuals and organisations stall.
At Level 2, the Eloquence Trap is at its most seductive. The user has learned to “prompt” effectively. They see 40% quality gains in creative tasks (Harvard/BCG, 2023) and believe they have mastered the tool. However, they are still operating “passively.” They are the “Passengers” who, when the AI’s “Jagged Frontier” (the limit of its capability) is reached, fall off the cliff. In the Harvard/BCG study, while AI increased performance for tasks within the frontier, it actually decreased performance by 19 percentage points for tasks outside it, because users failed to verify the logic.
To move to Level 3, one must undergo a Subject-Object Shift. You must stop being “subject to” the AI’s fluency and start treating the AI as an “object” to be interrogated. This requires engaging the Institutional and Deductive layers. It requires the “Human Mirror” - the willingness to say, “The AI says this is the answer, but my experience and our firm’s data say otherwise. Why?”
This transition is the “Knee of the Curve.” It is where the Brynjolfsson J-Curve is most pronounced. It feels like a step backward. It is slower to verify than to generate. It is harder to think from first principles than to “Iterate with the AI.” But this pain is the price of Sovereign Command. Without it, you are simply a faster producer of more sophisticated noise.
Conclusion: The Sovereign Question
The 0-6 Maturity Scale is not a judgment; it is a diagnostic for survival. In an era of Power Law returns, being “good” (L2) is a precarious position. It is the position of the “Commoditised Expert” - someone whose syntax can be mimicked, whose context is shallow, and whose verification is non-existent.
The question for every leader and every professional is not “Are we using AI?” but “How high do we want to go?”
If you remain in the Passenger Band, you are a cost centre waiting to be optimised. If you move into the Architect Band, you are a value creator. If you reach the Orchestrator Band, you are the one who defines the future of your industry.
The path to the top of the scale is not paved with more tokens or better models. It is paved with the rigorous application of the Five-Layer Knowledge Model and the courage to face the Human Mirror.
Where are you today? And where will you be when the curve turns upward?