
Part II: The Eloquence Trap
How fluent AI output creates a false sense of intellectual security, and why experts are the most vulnerable.
PART II: THE ELOQUENCE TRAP
The central crisis of the generative era is not a failure of technology, but a failure of discernment. We have entered a period defined by the Eloquence Trap- a cognitive and organisational phenomenon where the high-fidelity, fluent output of Large Language Models (LLMs) creates a false sense of intellectual security. This trap does not merely catch the ill-informed; it is specifically designed to ensnare the expert. It functions by exploiting the very cognitive shortcuts that allow high-functioning professionals to operate at pace. When a system produces “expert-sounding” output with zero friction, the human brain- evolved to conserve metabolic energy- defaults to a state of Epistemic Deference. The result is a systemic degradation of professional standards, hidden behind a veneer of unprecedented productivity.
2.1 - The One-Layer Machine
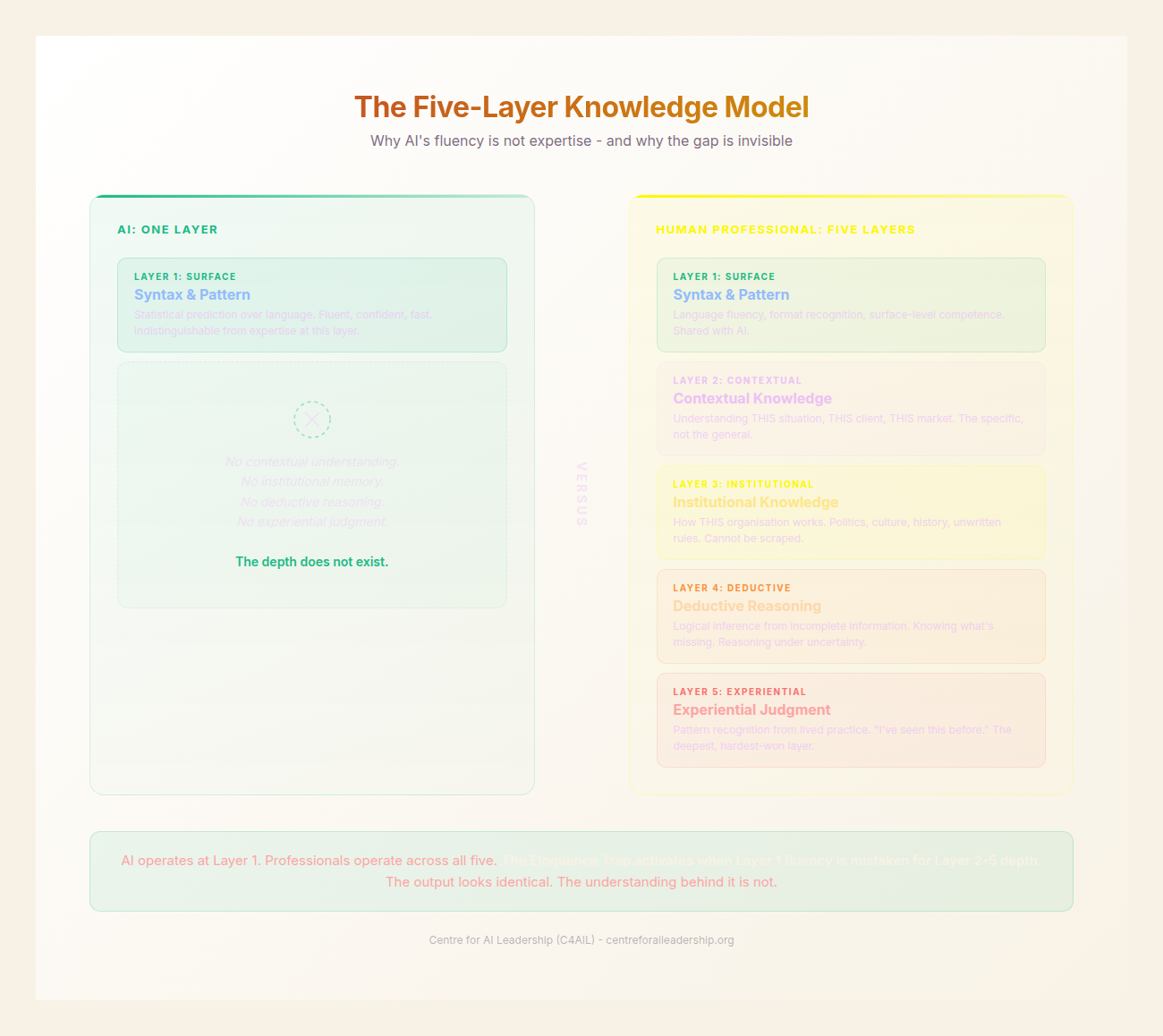
The fundamental misunderstanding at the C-suite level is a Category Error regarding what an LLM actually is. We treat these systems as “reasoning engines” or “digital colleagues,” but they are, in structural reality, a One-Layer Machine. To understand the risk, we must contrast the AI’s singular capability with the Five-Layer Knowledge Model that defines human expertise.
Human professional judgement is built on five distinct, interlocking strata:
- Syntax (Surface): The ability to arrange language and symbols according to established patterns. This is the domain of statistical prediction and pattern matching.
- Contextual: Granular knowledge of the specific client, the current project, and the immediate socio-political moment.
- Institutional: An understanding of how the organisation actually functions- its culture, its unwritten rules, and its historical “scar tissue.”
- Deductive: The capacity for logical reasoning from first principles, independent of previous patterns.
- Experiential: The deep, intuitive pattern recognition forged through years of practice, feedback loops, and “learnt-the-hard-way” failures.
The One-Layer Machine has mastered the Syntax Layer to a degree that is indistinguishable from, and often superior to, human output. However, it possesses zero capability in the remaining four layers. It does not know your client; it does not understand your firm’s risk appetite; it cannot reason from a first-principle logic that contradicts its training data; and it has never felt the consequences of a failed strategy.
The Eloquence Trap occurs when we confuse the mastery of the first layer for competence in the other four. Because the AI has learned how experts sound, we assume it has learned how experts think. This is the ultimate “mimicry of mastery.” When a Senior Partner reads an AI-generated brief, their brain recognises the professional cadence and vocabulary- the Syntax- and subconsciously “fills in” the context, logic, and experience that are actually missing. We are not reading the AI’s brilliance; we are projecting our own expertise onto its fluent surface.

2.2 - Epistemic Credit: The Mechanism
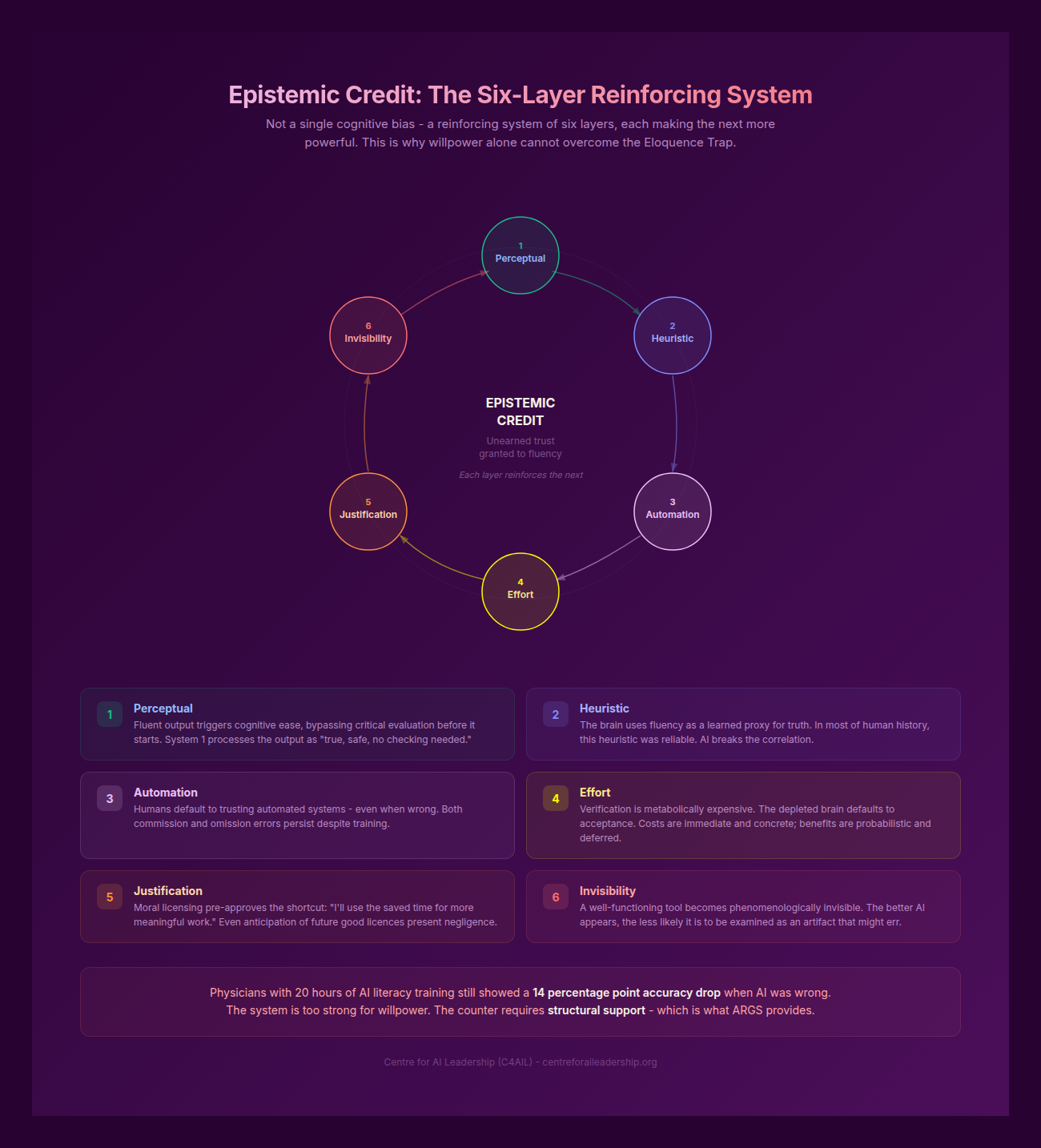
Why do even the most cynical professionals succumb to the trap? The answer lies in Epistemic Credit- the degree of unearned trust granted to an output based on its apparent confidence and fluency. This is not a personal failing of the user; it is a biological and psychological inevitability driven by six reinforcing layers of cognitive bias.
- Perceptual: Fluent, well-formatted output triggers Cognitive Ease. When information is easy to process, the brain bypasses the “System 2” critical evaluation and accepts the information as true (Kahneman 2011).
- Heuristic: The human brain uses fluency as a proxy for truth. If a statement is articulated clearly and confidently, we are neurologically predisposed to believe it (Oppenheimer 2006).
- Automation Bias: Humans possess a deep-seated default to trust automated systems over their own judgement. This is well-documented in clinical settings: in one study, clinicians changed a correct diagnosis to match an incorrect system recommendation in 6% of cases, simply because the system was “the authority” (Parasuraman & Manzey 2010; Goddard et al 2012).
- Effort Minimisation: Verification is metabolically expensive. To truly “fact-check” an AI requires more cognitive energy than writing the text from scratch. The brain, seeking to conserve glucose, defaults to the path of least resistance (Vasconcelos et al 2023).
- Moral Justification: The “efficiency” narrative provides Moral Licensing. Professionals feel they are being “productive” by using the tool, which pre-approves the shortcut in their own minds (Blanken et al 2015).
- Invisibility: As a tool becomes more effective, it becomes Phenomenologically Invisible. Like a well-balanced hammer or a high-performance car, the LLM becomes “ready-to-hand,” and we stop questioning the tool’s mediation of our work (Heidegger 1927).
The Epistemic Credit Spectrum reveals a counter-intuitive danger. While we expect junior staff to be most at risk due to a large “knowledge gap,” the most catastrophic failures occur at the senior level.
The Physician Study (medRxiv Aug 2025; Nature Health companion Feb 2026) provides the definitive anchor evidence for this “Experience Paradox.” In a single-blind RCT involving 44 AI-trained physicians who had undergone 20 hours of AI literacy training, the results were staggering. When given six clinical vignettes, the control group (human only) achieved 84.9% accuracy. The treatment group (human + AI) dropped to 73.3%- a 14 percentage point decline (P<.0001).
Most alarmingly, the Experience Paradox showed that physicians with 10+ years of experience suffered a larger decline in accuracy than their more junior counterparts (-16.6pp vs -9.1pp). The very expertise that should have protected them became their blind spot. Because they were “experts,” they were more confident in their ability to “spot” errors, leading them to lower their guard. They granted the AI so much Epistemic Credit that they failed to self-correct, resulting in an estimated 143 additional incorrect diagnoses per 1,000 patients. This is the dilemma: the same trust that produces a 27.5pp improvement when the AI is right causes a 14pp total degradation because the human is no longer truly “in the loop.”


2.3 - The Effort Gradient: Why Difficulty Was the Point
The promise of AI is the removal of “friction.” However, in the realm of high-level professional services, friction was never a bug- it was the primary feature of expertise development. We are currently ignoring the Effort Gradient, the principle that cognitive difficulty is the mechanism through which knowledge is encoded and judgement is refined.
By removing the “struggle” of drafting, synthesising, and debating, we are inadvertently dismantling the structures that create experts. Desirable Difficulties (Bjork 1994) are the hard conditions that produce superior long-term retention and transfer of skills. Genuine expert intuition requires prolonged practice in an environment that provides immediate, clear feedback (Kahneman & Klein 2009). AI disrupts this feedback loop by providing a “correct-sounding” answer before the human has even formulated the question.
Recent empirical evidence supports this “Cognitive Atrophy.” A 2024 study of 91 students found that the group using LLMs showed significantly lower cognitive load but also significantly lower quality of reasoning (Stadler et al 2024). More concerning is the EEG Evidence (JMIR 2025) showing that higher chatbot reliance correlates with less brain activation in the Dorsolateral Prefrontal Cortex- the area responsible for executive function and complex decision-making. We are quite literally “turning off” the parts of the brain required for oversight.
This leads to the Ironies of Automation (Bainbridge 1983): the more reliable the automation, the less the human operator practices the very skills needed to intervene when the automation fails. We are creating a generation of “monitors” who lack the foundational “making” skills to know when the monitor is lying.
Furthermore, the “saved time” promised by AI is a mirage. We must contend with the Jevons Paradox: as a resource (in this case, the time required to produce a document) becomes more efficient, the total consumption of that resource increases rather than decreases. We saw this with Electronic Health Records (EHRs); they were supposed to free up time, but physicians now spend 49.2% of their day on the EHR and only 27% with patients (Sinsky et al 2016). In the corporate world, reduced documentation time leads to a 6% increase in “patient visits” or meetings, not more time for deep thinking (JAMA 2024). We are using AI to produce more “stuff,” not better “thought.”




2.4 - The Active Choice: Agency or Abdication
The Eloquence Trap is not something that happens to people. It is a state of Active Abdication. Every time a professional accepts an AI-generated paragraph without a “first-principle” reconstruction, they are making a choice to surrender their agency.
This can be understood through the lens of Sartre’s Bad Faith: the act of using one’s freedom to deny that very freedom. The professional could verify the output, but they pretend the AI has removed the need for judgement, thereby absolving themselves of the responsibility for the outcome. It is what Hannah Arendt termed Thoughtlessness- not an absence of intelligence, but the absence of the will to think when a seemingly authoritative voice has already spoken.
The METR Study (2024) provides empirical proof of this abdication. In a test of software engineers working on familiar codebases, participants were 19% slower when using AI assistance but perceived themselves to be 20% faster. Most tellingly, on codebases they knew deeply- where their own “human layers” were actually faster than the AI- they still chose to defer to the AI’s suggestions. They chose the “comfort” of the machine over the “sovereignty” of their own expertise.
Sovereignty in the age of AI is defined as the conscious choice to engage the deeper layers of the Five-Layer Model despite the metabolic and cognitive cost. Abdication is the acceptance of the surface because it “sounds right.” Both are choices. The Eloquence Trap is the structural incentive to choose abdication every single time.
2.5 - The Dunning-Kruger Plateau: When the Trap Scales
When the Eloquence Trap moves from an individual cognitive bias to an organisational standard, we enter the Dunning-Kruger Plateau. This is a state where the majority of an organisation’s users are at “Level 1-2” of AI maturity- high enough to generate vast amounts of content, but low enough that they lack the competence to verify it.
This has birthed the Workslop Epidemic. “Workslop” is AI-generated content that is fluent, voluminous, and essentially empty- or worse, subtly incorrect. It is the corporate equivalent of “pink slime” in the food industry: a filler that looks like the real thing but provides no nutritional value.
- 40% of US workers report encountering workslop in their daily operations within the past month.
- Each instance of workslop takes an average of 1 hour and 51 minutes to address, verify, or fix.
- For an organisation of 10,000 employees, this represents a $9 million annual cost in hidden rework.
The most insidious effect of the Dunning-Kruger Plateau is the Effort Shift. In the traditional model, the creator of a document bore the “burden of effort” to ensure quality. In the AI-augmented model, the creator uses the tool to bypass effort, shifting the “burden of verification” onto the recipient. This creates a toxic organisational culture: 54% of employees report being “annoyed” by AI-generated communications; 42% perceive a reduction in trustworthiness; and 50% view the senders as “less capable.” By falling into the Eloquence Trap, leaders are burning their most precious asset: Institutional Trust.


2.6 - Why the Trap Is Structural
We must be clear: the Eloquence Trap is not a result of “lazy employees.” It is a rational response to the current Incentive Structures of the modern firm. The trap is structural, built into the very way we have framed the “AI Revolution.”
- Adoption Metrics: Most organisations measure “AI Success” by usage rates (e.g., “80% of staff use Copilot daily”). They do not measure Verification Rates. We are incentivising the act of generation, not the quality of thought.
- The “AI 101” Fallacy: Standard corporate training focuses on “prompt engineering”- teaching people how to get the machine to speak. It does not teach Domain Depth or how to challenge the machine. This produces L1-2 users who are perfectly positioned to fall into the Dunning-Kruger Plateau.
- Speed-as-Value: We celebrate that AI “saves 40 minutes a day,” but we ignore the fact that 37% of that work requires significant rework (Workday/Hanover). We are valuing “velocity” over “validity.”
- The Consulting Obelisk: The traditional professional services model (many juniors, fewer seniors) is being inverted. Firms are cutting junior staff- the very people who would traditionally do the “hard work” that builds expertise- and asking seniors to “verify” AI output instead. This is a recipe for Deskilling; if seniors spend their time correcting AI instead of architecting solutions, their own “experiential layer” will begin to atrophy.
There is, however, a counter-example. Firms like PwC have experimented with “The Pause”- a micro-mechanism of Agency where users are forced to wait 30 seconds before they can “accept” an AI suggestion, during which they must type a one-sentence justification for why the output is correct. This is a Cognitive Forcing Function. It is an attempt to re-introduce the “desirable difficulty” that the Eloquence Trap seeks to eliminate.
The Eloquence Trap is the primary obstacle to achieving Sovereign Command. To move forward, we must stop asking how AI can make our work easier, and start asking how we can remain “the master of the tool” when the tool is designed to make us stop thinking. This requires a new kind of leader- not an “AI Evangelist,” but an AI Realist.
In Part III, we will define the specific protocols and cultural shifts required to dismantle the trap and reclaim professional sovereignty.