
DeepSeek: The Greatest Growth Hack of All Times meets its David in a Chinese Quant.
How to bring down Big Tech AI domination with a bunch of H800 cards, some nerdy science and Open Source.
🐍 Happy New Year 🐍
Usually I write an end of year review around the end of the year. This year, I’m a bit late with that, but the following should make up for that, fittingly about Chinese AI red packets in time for the Year of the Snake.
🏮Gong Xi Fa Cai from Singapore 🍊 — Georg
The Leaning Tower of Big Tech AI Manifest Destiny
The end of Zero Interest Rate Policies in response to the pandemic heavily stunted Big Tech growth prospects, as did the slowing growth of the internet overall in the world. These challenges, barely three years ago saw tech stocks at record low, depriving them of their power and vulnerable to attack. Twitter’s fate was a warning to everyone.
The advent of AI, or rather a new narrative of AI came to the rescue, just in time … and that narrative was is not “AGI”, “Agents” or even “Productivity Increase” and tech workers, tech influencers, consultants, media, foreign governments were not the target:
For the last two years, an investor narrative around AI emerged that only Big Tech companies, with planet-scale data, the platforms to harvest it and the infrastructure to process it into models could be competitive in foundational AI.
This narrative did not come out of nowhere, it was shaped and positioned by the largest players in the space and underwritten by massive investments and even more eye-popping fundraising narratives:
- Nvidia’s meteoric rise in and beyond the trillion dollar market cap club.
- OpenAI’s record unicorn valuation, losses and ever increasing hunger for more investment.
- Meta’s spending of a Manhattan project’s worth of money on AI in a single year, and more in the future.
- Sam Altman floating fantasies of trillion dollar investments to achieve ill defined AGI.
- Startups like Perplexity achieving multi billion dollar valuations on a hallucinating LLM, a slightly different search user-interface without ads and monetisation strategy, backed by the same Big Tech Club.
Investors, unwilling to bet that “so much money could be wrong”, had little choice but pile into these MegaCap stocks in order to benefit from the next big thing in tech.
Soon, the public was told, the entry requirements to do AI would be your own Nuclear Powerplants and the price to pay would be worth it.

The possibly greatest growth hack of all time
Once one understands the very simple truth that a handful of US technology companies managed to capture and concentrate the new technology frontier that is AI, with all it’s yet to be explored riches, a lot of things start making sense:
- The excessive, even maniac pace of fundraising, all in service of future promises.
- The constant stream of “breakthrough models”, trained for tenths of millions for their brief moment on top of the benchmarks before being dethroned and forgotten without any prospect of ever producing value.
- The stream of AI products like GPT Platform and Dall-e, released and then left to rot with minimal investment, which does not track with any intent for long term value.
- The relentless push against against ESG, especially sustainability, handwaived away with “AGI will fix climate change”.
- The buzzword jumping, from Agents to AGI to ASI and memetic teasing of breakthroughs to keep the faithful engaged with little real to show for.
- The naive “if we just throw more energy at it, the goal is assured” with it’s log scale graphs and ever growing infrastructure costs.
- The race to an undefined, ever shifting goal a without clear path beyond.
- AI being aggressively pushed pushed into every facet of the economy from healtcare, to government, to robots before there are even usable products.
All of these contradictions fall into place when you understand the nature of the play. At the root, still, there’s a need for infinite growth and “inefficiency as value concentration” may very well be the most successful growth hacking strategy ever conceived in the Mecca of Growth Hacking, Silicon Valley.
The new version of AI Manifest Destiny, from wallet to shiny wallet was going to require every little bit of power and infrastructure, preferably given to Sam Altman’s Power Investments to ensure AI supremacy by winning the race to an undefined future. ..but let’s not focus on the details, the important part was that the US just need to get there before China, and, of course, the money.
By the rules of capitalism, this race can never end, and by the rules of capital, the stakes have to continously grow.
But technology is flexible. Positioned as General Purpose Technology, AI can be imagined into any sector of the economy: Healthcare, Finance, Robots. And every segment touched by AI will have it’s future investments drained into Big Tech’s ever growing AI MegaCap Tower. $500B infrastructure investments are inevitable when you’ve cleaned out the sub-$100B segment of the market. By transcending onto national scale and into national infrastructure and eventually defense, more and more money can be attracted, no extracted into growing the tower.
It’s beautiful in it’s simplicity, and it should scare the hell out of everyone.
China has a role to play here, unwittingly. It doesn’t matter what their real plan or intentions were, because every race needs competitors and they are the only credible racer available. And, as we found out this week, one of China’s racers decided to change the rules.
The Stock is the product
If this all starts sounding familiar, it should.

The one thing to understand about Silicon Valley growth companies is that “The Stock Is The Product”.
That is the primary business business model, technology itself is secondary. The value of AI therefore is not the technology, not models, not AGI, but the market narrative they create.
For the last few decades, Big Tech has been been the place to grow money - not by accident, because it’s an industry that has made growth it’s core objective. In a Big Tech company, shareholder value is the first step of the long range planning cycle, and it is the output of every action taken, self re-inforcing: Stock based compensation buys and locks in the best talent in the world, Stock heavy M&A deals, are a key weapon for suppressing competition and to enable future growth.
Stock therefore is power, on loan from shareholders expecting more in return, and as we saw in 2024, with the right narrative one can amass enough power to change the frame of reference, even the political system itself if it threatens future growth through regulation or other means.
And at the moment, the one thing that holds all that power, all that capital in one place is a singular idea:
Only Big Tech companies can do AI.
But before we go into those details, let’s look at another event that foreshadowed what was to come:
Prelude: Kokoro-82M
Just a few weeks ago, before Deepseek R1, a model was released by a single contributor named “hexgrad” on HuggingFace.
Kokoro-82M is a Text-To-Speech (TTS) model trained using an Open Source recipe on a single A100 GPU in with less than 100 hours of audio for a grand total of $400. It achieves State of the Art consistency at exceptional speed (Real Time factor of 0.01-0.05, 50-100x real time) on mid-range consumer hardware.
Kokoro-82M shows dramatic, orders-of-magnitude efficiency gains and can power use cases like Real Time Chatbots (remember OpenAI’s ScarJo Demo) at a pricepoint of approximately $0. To put it into perspective, the previously leading Open Source model was trained on 10.000+ hours of audio at corresponding cost and achieves lower performance and while kokoro is not beating the best proprietary models (such as ElevenLabs and OpenAI’s Voice Model) in quality, it establishes a new “Good enough for many use cases” tier of model for real time voice at insane efficiency.
With open source models like Kokoro available for free, how much of the Real Time voice market is left for proprietary offerings? After audio, what else may follow? If everyone can train a model of such quality and efficiency, what else can they train? At 6$/h, is OpenAI’s real time voice market dead yet?
Enter Deepseek
Deepseek is a financial quant shop, and a very successful one at that. That’s important, for later, and not just to explain why they had tons of GPUs sitting around.
DeepSeek has been at the cutting edge of tech for years, heavily invested in AI for their primary business and their talent is world class. They’ve been playing around with AI for a while and introduced some clever ideas, like Multi Head Latent Attention (MHLA), into the large language model space.
The two most recent model releases and technical reports by Deepseek, DS-3 and R1, are impressive work, building on top of the current state of the art in Open Source and advancing it in very material ways, advancing, for the first time, an Open Source model into the top tier of LLM foundation models.
Understanding “Reasoning” or CoT models like R1
Without going into too much detail, the primary difference between these models is that for traditional models you have to manually design the best prompt (with CoT Prompting being one option of how to do that)
O1, r1 and other “CoT” models are trained to automatically perform this “prompt engineering” on themselves, using the initial prompt as a starting point.
This process (“thinking”) is expensive, using inference time compute, and not always the right choice - human crafted prompts on a traditional model will often outperform CoT by a significant margin and is usually faster and cheaper.
One of r1’s major inventions is that it reproduces OpenAI’s summer breakthrough that lead to o1 and improves on it in significant ways, including the ability to teach other models (such as LLamas) to think (distillation).
Much has been written about these improvements, so we’ll skip this here (This report is a good primer), but we should note that most serious AI experts agree:
- DeepSeek’s talent is world class.
- Their scientific advances are clever and are advancing the state of the art.
- Their model performance is impressive.
- The efficiency gains in training and inference are real.
- Their use of RL to train the reasoning abilities in the model is excellent and will have implications well beyond R1.
- And yes, most people probably agree that they leveraged better models to bootstrap their work (because everyone does that).
There’s some denial and bargaining, especially in US Tech Circles, mostly insinuating that DeepSeek may have cheated by using more GPUs, but from current information and reproduction attempts, everything seems to check out.
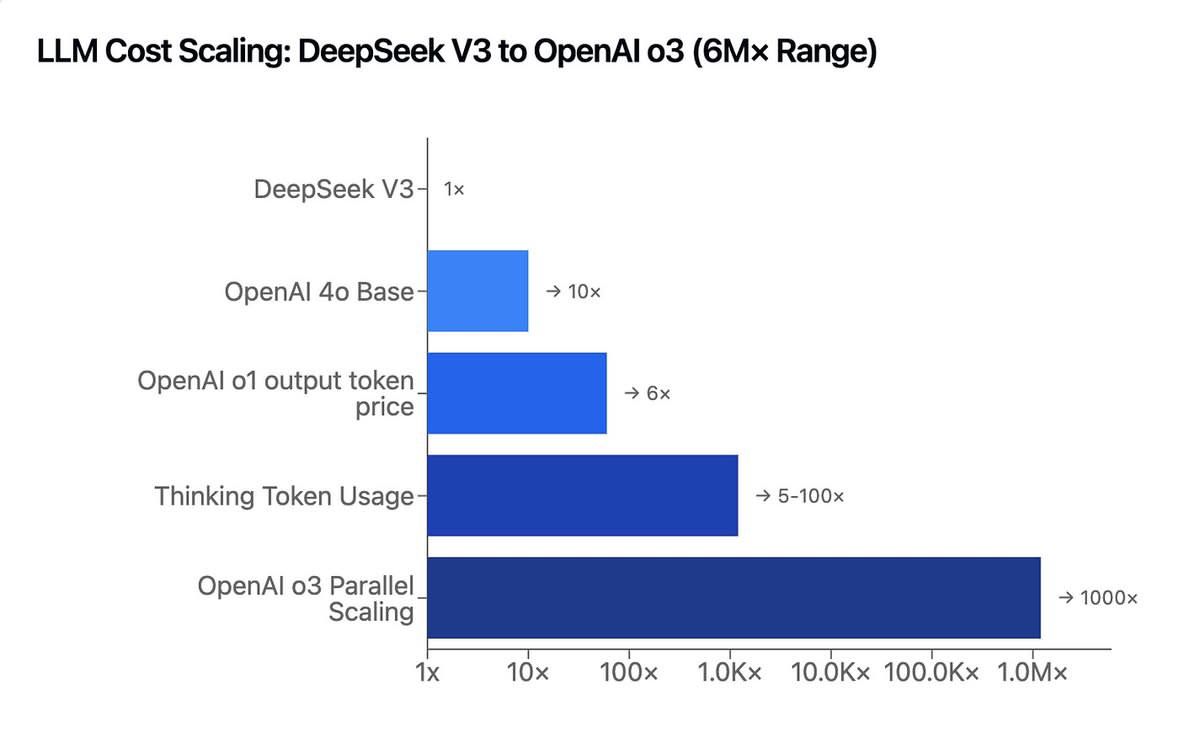
There are also many efforts in progress to reproduce DeepSeeks work from the technical reports they provided, and some of them are already reporting successes.
And of course this article would be incomplete if we wouldn’t mention the possibility that it was US Chip Sanctions that force Chinese developers like DeepSeek to focus on efficiency, which seems like something extremely obvious to do.
Unless, of course, the plan was to use inefficiency as a moat, which, as it turns out, is almost as stupid as it sounds (although I’m sure few shareholders at the beneficiary tech companies would complain about it). The memes commenting the situation on Chinese social media capture the sentiment well:
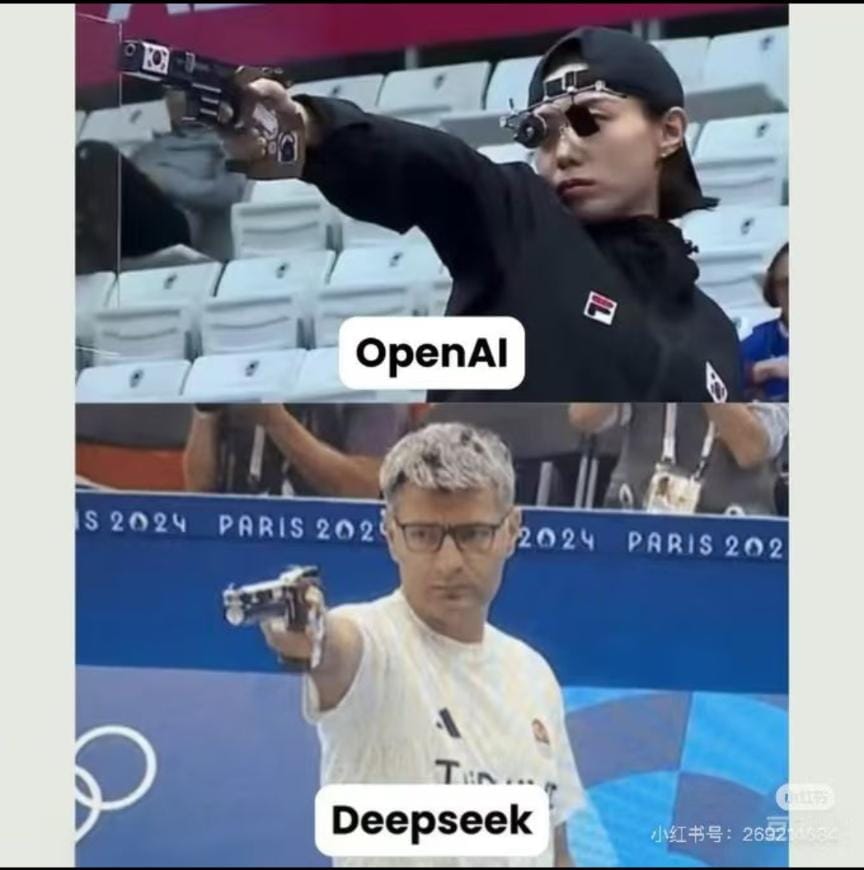
Efficiency and arrogance as the achilles heels of US AI Dominance
By demonstrating these improvements in an easily accessible model, and sharing the science into open source, DeepSeek created the perfect missile to strike at the foundation of the “AI is for big players only” narrative moat, turning Big Tech’s greatest strength (fundraising) into a vulnerability. For whatever reason, US tech companies did not see it coming.
In this new, post R1 world, top end AI models can be trained with the financial means of a medium size business leveraging recipes available in Open Source. And not just “wink wink” Open Source like Meta’s Llama, but permissively MIT Licensed Open Source with an invitation for reuse without limitations.
In this new world, training and operation of these models need orders of magnitude less resources, defeating the “nation state infrastructure spend” entry barrier into the foundation AI club.
In this new world, nobody will make their R&D money back, ever because cheaper AI will be everywhere, commoditized and operated at low margins.
And if this new world is real (a large part of America’s investor sphere is still in the denial stage about that), then Big Tech just burnt massive amounts of investor capital in glorious GPU fires only to be overtaken by a bunch of finance bros doing science for fun (and probably profit). The next earnings call for Sundar, Mark and the AI-bro gang is going to be painful.

It certainly leaves one to wonder if we’re watching an accidental convergence of factors or one of the greatest strategic deployments of science and research in the history of modern technology, exploiting the structural weakness in the whole US AI ecosystem (more on that later)
Strategic Coincidences
At this point US based commentators are usually quick to point out that there must be a sinister red shadow driving the DeepSeek attack, how else could a bunch of autistic finance auteurs beat the world’s most dominating technology companies?
People like Scale AI CEO Alexander Wang are quick to stoke those thoughts, firing off emergency letters to the President pointing at the supposed Red Menace and, of course, asking for nation state level investments to keep the GPU furnaces burning towards victory. This would, of course, be purely motivated by patriotic thoughts and have nothing to do at all with the precarious position of his business in this new world. Competition, it’s inconvenient sometimes.
As a former BigTech person, I see no shortage of explanations, including the impact of sustained, indiscriminate layoffs, the typical problems that appear in orgs with unlimited funds access and the prevailing group think in Silicon Valley.
And as someone with extensive background in technology and technology policy, I don’t think a “coordinated nation state strategy” is at play here. To me, there’s much more logical explanations:
Follow the Money
For one, money is a great motivator, in China just as much as in the US. The vulnerability of Big Tech’s narrative was visible to everyone, including companies with deep backgrounds in trading and market making. Unlike the average observer on the street however, it looks like at least one of such companies, DeepSeek did have the means to exploit such a vulnerability.
Whether or not they are doing it for nerdy fun, doing it to build a new business or they have a bunch of volume trade shorts lined up in the market, we’ll probably never now. But we do know they like money.
And with the hype infused discourse and social media attention ecosystem ready to blow up every minor tidbit about AI into “breaking news” and “game changers” narratives, it’s not hard to predict how an understated but very real model release with excellent benchmark performance and frame-of-reference shifting efficiency is going to be received in the market. Not hard at all.
Probably not official business
While the usual suspects won’t be satisifed with this statement, I really do not think this model release was coordinated in the market.
Primarily because I do not think this comes at an opportune time for China, strategically:
It carries a predictable, high risk of giving Donald Trump’s new administration a valuable tool to unite his squabbling tribes of Christian Fundamentalists, White Supremacists, Aggrived CryptoBros, Republican Hawks, Q-Anon Conspiracy theorists, e-Accel cultists and Opportunistic TechBros after they have finished doing what they can all agree on: Tearing down the system.
Faced with the prospect of 69% of the US electorate who didn’t vote for “reset” pushing back and the inevitability of his warring tribes turning on each other, a foreign threat to unite the country on would be exactly what he needs and if the DeepSeek moment creates a sufficiently large market impact, it may provide just that.
The future of AI, 0AD
In year 0 After DeepSeek, the world is changed.
For one, America is awakening to a world where their most powerful companies have been inflicted a devastating blow to ego and, likely wallet.

In theory, global governments, but especially the US Government should be furious by what happened here. Investors got defrauded, at least by intentional neglect (we should remember that Tech Companies are notoriously efficiency oriented and that much of their arcane hiring processes require deep understanding of performance tradeoffs to pass). In theory, the damage to the market, the environment and especially public funds collected on the faulty narrative should warrant congressional hearings and investigations. But given the closeness of the Tech CEO oligarchs to the new political power elite in the US, these consequences seem unlikely.
With headlines like “Chinese overtake US, Dominates in AI”, the average American meanwhile may start to question why it is only US companies ever fervently invoking images of AI Race, War for AI Domination and AGI supremacy. Or maybe they will ponder whether giving the AI CEOs too much money for GPUs may have caused more harm than good, especially considering what the Chinese developers seem to be able to do when you try to take their GPUs away.
But likely, they’ll just sit and watch the show unfold, because DeepSeek emerging from the deep was just the start of the party…
Chinese Techno Capitalism is Scary
Contrary to what some Americans believe, Capitalism is alive and well in China. Extremely well in fact. A smarter person than me recently described it as “That pit from the Batman Movie - only the most determined one ever climbs out, and that is a scary competitor”, and that’s pretty apt. If you want a good primer on the subject, read this
 Within days of Deepseek’s bombshell, many of the leading Chinese AI labs have started unloading their advancements:
Within days of Deepseek’s bombshell, many of the leading Chinese AI labs have started unloading their advancements:
-
Alibaba’s Qwen2.5-1M is an impressive, multimodal, open source model featuring a massive 1 million token context window and a direct message to Google, whose Gemini model currently rules the top of the token window competition, that they are next.
-
Minimax, a Shanghai based AI shop, released MinMax-01 into OpenSource, an impressively performing frontier model competitive with the best US offers incorporating several advancements, including an even more impressive 4 Million token context window.
While this may look like a coordinated, and many US commentators undoubtedly will see a the sinister hand of the Chinese government marshalling it’s forces in the AI war, it’s very likely not.
These companies are engaged in the same brutal competitive struggle as their American competitors, and that requires the same type of flashy investor virtue signalling (“Look, we cloned Scarlett Johansson!”) and one-upping each other that we see from Google, OpenAI and Meta.
Mr Altman, Damage Report!
For another, it seems that Chinese Technology is a lot harder to get rid of than some people thought. Following RedNote as the unofficial successor of TikTok, DeepSeek is now on top of the AppStore. The “data risk” hawks are going to have a field day with that.
In terms of immediate damage, OpenAI looks grieviously hurt. Coming fresh of a lukewarm victory lap of dangling $500B infrastructure investment (that may look insanely overprovisioned now and may or may not exist) as a potential exit to early investors, they are confronted with the prospect of a rapidly breeding army Reinforcement Learning powered Chain of Thought Whale-Llama, propagating all over the planet and posing an immediate threat to those 200$/month o1 subscribers draining OpenAI’s wallets slower than any other user.

But there are a few other, longer term lessons and implications that are worth considering:
1. You (really) cannot outcompete Open Source
If you do not have structural moats, such as expensive infrastructure, compute or attention platforms, competing with Open Source is very very hard.
This is not a new truth, but somwhere along the line of binging on VC cash, this seems to have gotten lost.
The anonymous, mid level Google employee who wrote “We have no moat, and neither does OpenAI” was in fact entirely correct, as everyone is now finding out the hard way.
When the Microsoft and OpenAI alliance launching their ChatGPT Bing attack on Google, Mark Zuckerberg immediatly understood that half a decade of frozen conflict between platforms was about to go hot and, rather than trying to sell investors the need to raise OpenAI-much dollars to build a proprietary model to compete, chose to Open Source as a defense strategy.
Meta, over the years, has strategically deployed Open Source to further it’s business interests:
-
React, for many years, provided some control over the UX of Apple’s and Google’s phone platforms while leaving the option open to launch a product eventually.
-
Sponsoring Pytorch not only murdered Google’s TensorFlow approach to ML and guaranteed Meta a front-, and occasional driver seat in the strategically important ML community (along with free technology development now worth billions), it also grants Meta the strategic option to disintermedia CUDA should the time and option arise.
Deploying the Open Source strategy for AI made perfect sense. Both Google and OpenAI were ahead, but bet on keeping AI proprietary and spending much of 2023 trying to lobby governments to give them a regulatory moat. After initially leaking Llama and encountering limited resistance from regulators, Meta went all in and gave the hungry Silicon Valley engineering community their first free, top tier LLM model.
For Meta the tradeoffs are excellent. Open Source provides basically infinite engineering resources at no cost, in exchange for not being able to develop proprietary technology and Mark correctly calculated that the first major LLM architecture to go open would become the defacto standard.

World Domination by Llama
Until now, everything played out exactly as intended. Llama went, within 2 years, from a single, barely passable LLM to a massive heard of leading models, benefitting greatly from architectural improvements and optimisations by some of the leading software engineers and researchers in the world, for free.
Tooling like llama.cpp alone represents hundreds of millions of dollars in top end product development Meta never had to pay for - in fact they were able to lay off more and more people to satsify their investors, all while their open source army started crushing Google and OpenAI on the tooling and product exploration front.
And even though Meta let the Llamas run free, and investing tens of billions of dollars to ensure their supremacy, it retained full control over the only competitive, in the wild open source AI model:
Without regular model refreshes provided by Meta to keep Llama state of the art, and ensure data freshness (especially for important use cases like Coding), all the tooling, open source infrastructure and applications would be left lagging behind the leading, proprietary options. A softer dependency than a proprietary API, but a dependency nonetheless.

And Meta was not shy about leveraging that control, strategically denying it’s deployment in the EU trying to break emerging regulatory walls.
Open Source for Meta is defense (against technology disruption), degradation of competition (by commoditizing AI and devaluing competitor technology), fundraising narrative, cost saver (the ability to compete with fewer product teams), future business engine (AI commoditizes digital creation, creation leads to more digital product, all digital product that wants to be sold must compete, usually on ads) and growth opportunity (new attention surfaces) all in one, a less direct package than selling Gemini or ChatGPT, but poweful nonetheless.

Unfortunately for Meta, Deepseek’s missile had another warhead: The MIT License
While DS3 was initially deployed under a permissive, but custom DeepSeek-3 license, R1 was licensed MIT, and that’s a direct hit, with massive implications for Meta.
By MIT licensing a better model and making it freely available, along with the science and technical papers, DeepSeek has executed a disintermediation attack on Meta’s control of the Open Source AI community: R1 is better, more open, faster, and cheaper to run.
Even worse, its distillation project can mount on top of any other model, training them into an “r1 distillate” able to perform CoT reasoning, as seen in the handily released ‘r1-distillate-llama70b’ model which can run on a home workstation and delivers o1-mini level reasoning performance at impressive speed. Ouch.
And it took only a few days between license change and the the market recognizing the implications and opportunities:
Within days of r1’s release, HuggingFace joined the “take Open Source control from Meta” party and announced the creation of the ‘open-r1’ model imitative, promising to reproduce and recreate a fully open R1 model, including dataset. Anyone at Meta harboring thoughts of leveraging insinuations about Chinese State Influence in the r1 dataset for FUD just had their playbook burnt, sorry.
The Whales have mated with the LLamas, and they are not coming home.
In the post R1 world, the best performing and most open choice for running AI privately is no longer a LLama and unless the now old, inefficient Meta can retool for speed and deliver greater value, it will be disintermediated.
Without creating significant performance or feature distance above what Deepseek and everyone else about to join the Open Source Foundation club at it’s new entry fee can deliver, control isn’t ever coming back to Meta, or, for that matter, anyone else. As Stability AI found out when Flux started splitting their Open Source community in 2024, better still matters, but so does openness.
 And somewhere in the EU, a bureaucrat is laughing…
And somewhere in the EU, a bureaucrat is laughing…
From China, To Europe, With Love
For Europe, having been meme chastised for “focusing too much on regulation and not spending enough on AI” for the last 2.5 years by VCs and tech community alike, suddenly finds itself looking pretty smart for not rushing head first into the FOMO.
 A helpful Chinese quant sent them a Red Packet at the dawn of the Lunar Year of the Snake stuffed with a full recipe to top-of-the-line models, a new open source model more open than LLama, not having to listen to Nick Clegg whining about letting Meta import LLamas anymore and the realisation that their future infrastructure deficit isn’t nearly as bad as they were made to belief. That’s pretty good!
A helpful Chinese quant sent them a Red Packet at the dawn of the Lunar Year of the Snake stuffed with a full recipe to top-of-the-line models, a new open source model more open than LLama, not having to listen to Nick Clegg whining about letting Meta import LLamas anymore and the realisation that their future infrastructure deficit isn’t nearly as bad as they were made to belief. That’s pretty good!
2. The future AI looks better, faster, more commoditized
The long term trend is clear: As we are getting better at understanding and optimizing this new breed of AI models, we keep finding additional ways of increasing efficiency. And all technological development eventually runs out of easy gains, there’s little indication this will happen anytime soon.
In fact, the DeepSeek technical papers provide a number of additional possibilities, especially around using Reinforcement Learning and distillation to shape model behavior beyond CoT that will likely spawn many more interesting breakthroughs. And with the new cost of entry, many more individuals and organisations will be able to join the frontier, exploring and discovering even faster.
With power cost of AI dropping by an order of magnitude, the attempts to “brute force” AGI will continue.
Any company previously using AI at 10x the cost, will now use 10x the AI at 1x the cost instead, commoditisation drives proliferation. What happens now, without doubt is a significant acceleration of AI, even if the investor money gets more limited. I worry about this, because even at current speed, AI has strained societies abilities to adapt.

The advances contained in DeepSeek will NOT just improve the positive usecases. Scammers will be able to scam 10x more with the same resources, RL reinforced, specialized ScamGPTs and BlackHat agents will be better, more powerful and more capable of inflicting damage. Nobody was prepared for the wave at 0.1x efficiency, but that wave just got a lot higher.
Nvidia is going to be fine.
While some may feel the urge to sell off Nvidia on the idea that cheaper training inference means lower sales, history tells us a different story:
Through the last 25 years in gaming, and 15 years in AI, over and over we have seen that pattern that better performance always leads to more AI use, not less. Give a game developer a GeForce 1070 and he’ll make a Game to sell a 2070. Give an AI developer a faster GPU and they’ll make models that require and even faster GPU.
Especially with AI video offering massive room to grow and burn carbon for AI cat videos on the quadratic journey to 8k/144fps real time video, Nvidia is limited by AI uptake, not efficiency and cheaper AI means more people using AI.
3. The Red Menace Playbook will be with us.
2024 was the year tech companies took sides in the American political system and started their march into the halls of power, with far reaching consequences: Their prefered cosplay as “the better choice than the government” when it comes to “safeguarding privacy” is no longer tenable and with alignment to an assertative and authoritarian president comes natural friction in the rest of the world. Balkanisation of the internet appears more and more likely, making tech companies even more reliant on the US government to pick up their endangered growth.
While nobody really seems to know exactly where the AI race is going, even the most naive e/accel cultist in Silicon Valley knows who the other racer is: China.

The common enemy serves as the convenient treat and boogeyman, and DeepSeek’s masterful technological play will only serve to further this narrative.
Without doubt, bountify military AI contracts will be given to loyal tech companies ready to fend off this threat, a development that should greatly worry everyone, especially given the non-existent state of AI governance and ethics in the world. And without doubt, it is only a matter of time because these AI developments, when flaunted to shareholders to ensure continued stock preformance, will trigger races all over the world into the same direction. The fact that AI is now exponentially cheaper than it was a few months ago only makes this a much more pressing concern.
2024 also showed us just how far Tech Companies love capitalism. TikTok, besting Meta’s algorithm by showing users more of what they want to see (as opposed to endless, but apparently profitable AI slop), found out: Until they stop winning. Fund managers, before the election, bet on these dynamics, and Tesla, correctly reasoning that a Trump win would guarantee the ban of Chinese EVs from the country and therefore benefit the stock.
We can expect this de-coupling to continue, forcefully since many US users, accustomed to constant data breaches by US organisations, don’t seem all to worry about Chinese products. TikTok’s data security narrative can seamlessly be transitioned to AI apps like DeepSeek and I would be very surprised if they can still be found in the US Appstore in a year. Beyond that, there’s the question of just how far the Trump administration would go to force trade partners and “allies” to do the same.
The coming Hunt for Red LLama
Sometime in 2023, Sam Altman tried his best to convince regulators locally and abroad that AI was about to go AGI and would pose a terrible doomsday risk unless sane, honest and highly ethical people like himself would be handed control. And that the worst case scenario was Open Source AGI in the hands of everyone. This didn’t play out, for one or another reason - Meta leak-dropping LLama among them.
Given the existential threat the new, multi headed Open Source AI movement is now posing to OpenAI, we can absolutely expect another attempt at trying to at least shut down Meta’s LLama efforts under the premise of giving “aid to the enemy”. “Did Meta Kill US AI?” is a sentiment in more than one commentary on the new Red Llama Menace.

How an Open Source ban could technically achieved (forcing Github and Huggingface to deplatform Chinese papers and models?) is questionable, but that hasn’t stopped any politician yet. The ultimate fate will likely be decided not by feasibility, but by how well Mark Zuckerberg manages to endear himself to the new King on Orange Throne in Washington DC.
4. The business fundamentals for AI have not changed, and neither has the war.
For companies like OpenAI, Microsoft, Google and Meta, DeepSeek’s attack primary impacts shareholder narrative and market positioning. The earnings calls in the coming days and future fundraising rounds will show if investor enthusiasm for big numbers has been dampend by recent events. Serious resistance here could spell the end of the AI party and the bleak task of trying to create a business model out commodity technology without significant margins.
It’s better news for the rest of the market. With the “must be big to do AI” narrative seriously damaged, more investors may find the courage to fund smaller shops building specialized models. Many of the industries shortcomings are due to the singular focus on building that one general model that does it all, but there’s good reason to believe that there are other options - and DeepSeek’s R1 paper shows that RL likely has a much larger role still to play.
On the technical front, without doubt, their engineering teams will be back-porting any of DeepSeek’s efficiency improvements to their own models. This may take longer for companies with proprietary technology stacks like Google and OpenAI, but ultimately will be only a bump in the road. Whatever money was burned on past models is gone.
While the Chinese model makers herald the opening of another front in the AI War and the potential rise of more challengers, their competition continues, as do the relentless growth expectations of the market. With these expectations, and the new competitive pressure, the underlying reasons for continued layoffs persist.

The underlying business fundamentals have not improved either, and they continue to look bleak. Cost, so far, has not been the defining reason why users and businesses have been shy to adopt their AI products as enthusiastically as they may have hoped. Therefore, it is unlikely that efficiency improvements and price drops alone will change this trajectory.
5. Some AI fundamentals have changed, but others remain.
An order of magnitude increase in efficiency is a serious limit break and will lead to new capabilities and inventions. But there are still a few limits that, so far, are not moving significantly, regardless of GPU or money spend and they are most useful to be aware of:
-
Prompt injection. The fundamentally unsafe patters of using a single input for both data and instruction into LLMs continues to be one of the major limiters to building products that operate on untrusted data (e.g. the internet). Current tech-demos glance over this point, but companies, especially in regulated environments do not have that luxury. Efficiency does not fundamentally change this limit, it’s been with us since 2017, but more available compute budget for mitigation measures will move the bar for some usecases.
-
Hallucinations. We already know these are “unsolvable”, and more compute will likely not make a difference here. RAG proponents often overestimate the impact of RAG on model induced inaccuracies, and even with the best available RAG measures, no model I am aware of currently exceeds 95% reliabily under real world conditions. And long as accuracy remains degraded in the sub 99.9% range, compounding error dooms any serious attempt at generalist, fully automated agents.
-
UX. Generalist Chatbots, once thought to be the face of AI, have disappointed in practical use and it is increasingly clear that the AI adoption will only be found in custom products that make AI accessible to users. Chinese Companies, in fact, have been leading on creating more realized product experiences. OpenAI’s Dall-e and Sora, with their rudimentary UIs appear to be more tech demos, significantly lagging their Chinese competitors in interface and usability. DeepSeek changes none of this.
Final thoughts
With Deepseek, we’re entered the next phase of the AI era. None of the many open questions about the technology’s trajectory, it’s potential and it’s economic promise have answered or fundamentally changed.
But we can say that Open Source is in the lead now and that from here on out, there’ll be even more AI, at lower cost, with ever increasing capabilities. I still have no opinion on AGI, but if it is a “society altering event”, it’s now in a race with the US trying to build a new system from an alliance of groups more diverse than Syria’s rebel groups.
At the same time, the world confronts the emergence of a new world order, with the US not acting as a leader building an alliance, but increasingly as a would be colonial empire compelling subservience with threats, economic and increasingly technical power projection.
With incredibly deep dependency on US tech company infrastructure in much of the Western World, the emergence of unencumbered Open Source is a welcome development outside the US, offering a small hope to at least avoid deepening existing dependencies.
The roadkill in this mad dash has been, as so often, sustainability. In the light of our increasingly dire climate crisis, Governments across the planet should ask themselves carefully if the technology industry, after all that’s happened, really deserves a carte blanche on energy and power to pursue their race to nowhere.
About the Author
Georg Zoeller is a Centre for AI Leadership Co-Founder, former Meta/Facebook Business Engineering Director, and Game industry veteran with roles at Ubisoft, Electronic Arts and BioWare Corp. He resides in Singapore.
He writes about the strategic implications of Artificial Intelligence, Technology and its impact on business and society from a backdrop of more than two decades of experience at the intersection of business and technology in Big Tech, Gaming, Fintech, SaaS and Consulting.
As C4AIL’s Chief Strategist, he supports decision makers in private and public organisations such as Meta, Netease Games, Mobily Etilsat and more on AI strategy, governance, policy and innovation.
He also supports AI programs for Singapore Management University, Singapore Institute of Management and is a co-designer of ai-bootcamp.org, a high intensity Bootcamp blueprint to accelerate software engineers to AI competency. He is the former human CEO of ai-ceo.org 🐍🛢️.