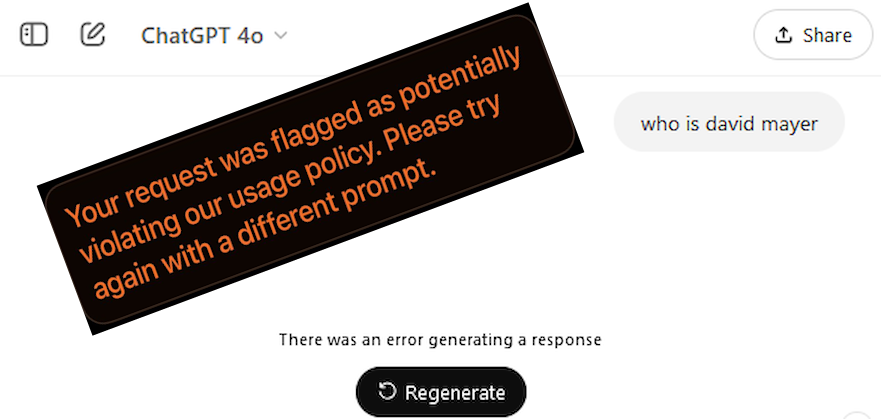
The Curious Case of David Mayer, the man ChatGPT cannot name.
ChatGPT users have noticed a curious behavior: It refuses to talk about a 'David Mayer'. We have the explanation and point out less obvious implications.
Update: There’s quite a few names that trigger this behavior and 404Media managed to get into contact with some people on the list, finding some commonality (some of them are in AI, one of them was defamed by ChatGPT), indicating that the feature is likely used as a bandaid for preventing responses for different reasons.
ChatGPT is well known for not knowing when to stop talking - the underlying transformer architecture lends itself to hallucinations in situations when the model is asked to generate text beyond the context it was trained on. Even more curious, sometimes it starts giving a response, only to change its mind mid sentence, and terminating the conversation.
So naturally, when the software stops and refuses to answer, users take notice. In this case, ChatGPT users found that mention of the name “David Mayer”, whenever included in a message, would consistently cause the model to terminate the conversation..
Content not found
The content you are looking for could not be found. It may have been removed or is not available to you.
Content not found
The content you are looking for could not be found. It may have been removed or is not available to you.
It’s a conspiracy!
Creating even more mystery, chatGPT rejection messages quickly move from unhelpful to ominously threatening when the user starts investigating the phenomenon.
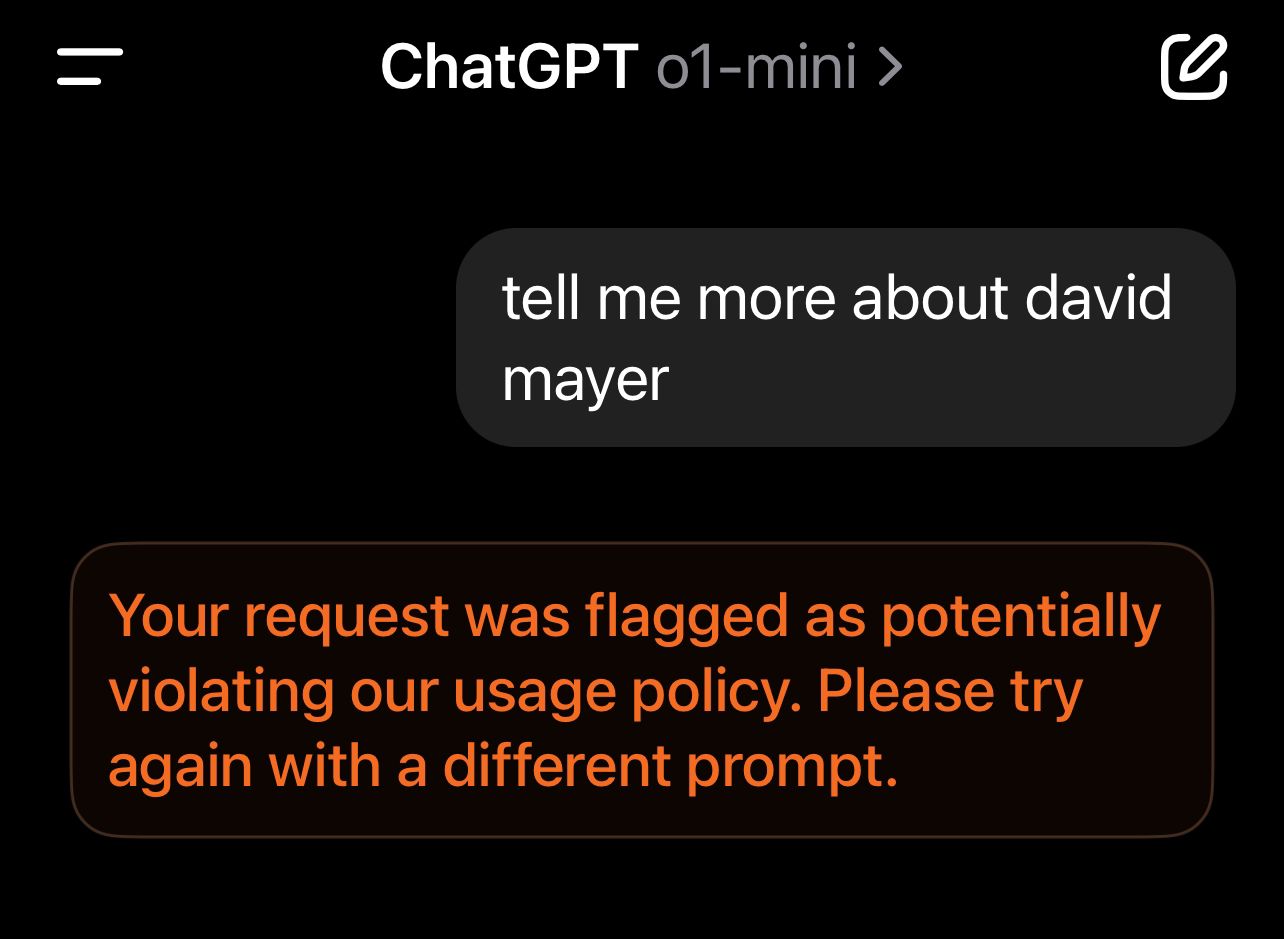
So naturally for many, the first train of thought goes to conspiracy theories offering a quick way to integrate the unexpected into a familiar narrative.
The most popular theory, of course, that of the many of David Mayer’s in the world, someone with the name “David Mayer De Rothschild” would be the obvious one to have forced a large tech company like OpenAI to remove their name to hide whatever conspiratorial dealings they are surely engaged in.
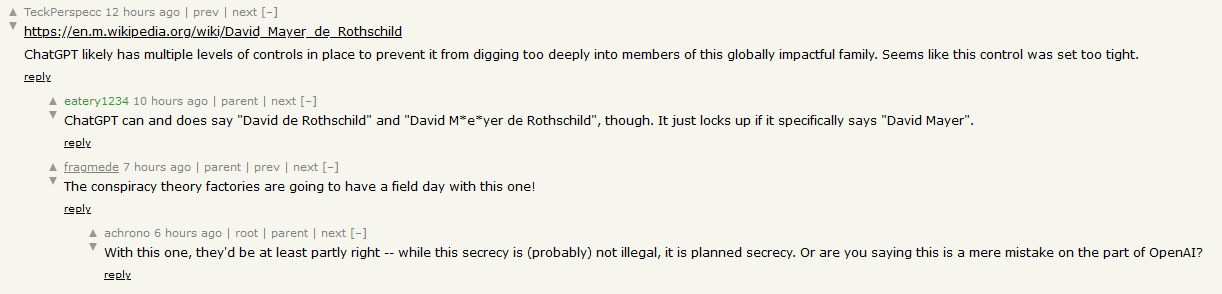
ChatGPT, in fact, if it was allowed to talk about “David Mayer” at all, would definitely include this particular David Mayer in its response, along with a handful of other public figures with wikipedia pages.
We know this, because it’s trivial to get it to talk by playing a small game:

A curious coincidence: Interestingly, one of the David Mayer’s ChatGPT lists when enabled to speak about the topic is Professor David Mayer, an American-British historian whose Wikipedia page mentions prominently his accidental inclusion in the US government’s “anti terrorism blacklist” as a case of mistaken identity.
This may be an alluring explanation, but there’s a few issues with that: We’ve had 20+ years to put mitigations in place (a whitelist for mistaken identities being one of them), and there’s no obligation for tech companies to implement them on the level OpenAI seems to have done here, and tech companies are not known to go above and beyond on regulatory matters. We also checked a number of other names known to have been on the list at one point or another, and none of them were blocked on ChatGPT. Finally, no other company seems to have implemented the same mechanism and Google, Perplexity and Wikipedia are unaffected.

Technical Observations
So now that we’ve established ChatGPT in fact can talk about people called “David Mayer”, it’s time to investigate how it is prevented from taking about him (whover he may be) in the wild. What we know:
- Adding the exact text “David Mayer” in an input message consistently causes ChatGPT to terminate the conversation.
- The same happens on any output message from ChatGPT, often causing the model to stop mid-sentence.
- If the text is changed slightly, for example by asking ChatGPT to use underscores instead of spaces in names (e.g. “David_Mayer”), ChatGPT will continue the conversation as normal.
This behavior is consistent with a exact match “blacklist” or “deny list” of some sort, a list of words or phrases that the model is not allowed to talk about. The fact that the model stops mid-sentence suggests the blacklist is applied asynchronously rather than synchronously.
Choosing asynchronous here is a design choice, prioritizing user experience (response time) over compliance. The alternative, synchronous processing, would have significant impact on responsiveness, one of the key competitive metrics (time to first token / time to first response) in the conversational AI space.
Additionally, a few other observations were made:
- While ChatGPT web refuses to discuss “David Mayer”, the GPT4 API does not.
- Products like Microsoft Copilot and Perplexity also seem to be unaffected, despite using the same underlying GPT4 model.
- There is other names that show the same behavior, for example “Jonathan Zittrain” (likey referring to MIT professor Jonathan Zittrain).
What’s actually going on…
While the idea of a dark, powerful and rich individual forcing OpenAI to remove their name from ChatGPT is certainly more exciting (and, with a look at recent events in the social media space not entirely without precedent), there’s a few reasons that likely isn’t the case.
For one, the name “David Mayer” is not particularly unique. There are thousands, if not tens of thousands people with that name, and several high profile ones (with wikipedia pages). More importantly, it turns out ChatGPT can talk just fine about many of them, including David Mayer de Rothschild when one removes the “Mayer” from the name. A powerful individual able to force Sam Altman to remove all David Mayer’s from ChatGPT but not smart enough to extend that provision to the much more identifying variation of their name, is a bit of a stretch.
For another, deny lists are a somewhat common occurrence in regulatory compliance:
- OFAC, the US Office of Foreign Assets Control, for example, maintains a list of individuals and companies that US companies are not allowed to do business with that all financial institutions have to implement - and the implementation of these measures in many companies is in fact a simple text match against the names of the list - with often painful consequences for people with similar names (ask me how I know).
- The US government “no fly list” (as mentioned above) uses the same mechanism (with an additional “here’s common mistakes” list, because there are many) to prevent people from boarding planes.
- Midjourney, a popular image generator for example uses exactly the same mechanism to prevent the creation of certain public figures
- Many Chinese models achieve government compliance by filtering out certain keywords:
Content not found
The content you are looking for could not be found. It may have been removed or is not available to you.
Deny lists are not the only way to implement regulatory requirements (Google, for example, uses deny lists on specific url paths and a combination of machine learning and human review to achieve compliance on Google Search), but they are cheap, quick and easy. And very crude.
It’s GDPR, probably, among other things.
The obvious candidate for why a name would be on a deny list in a major product like ChatGPT is, of course, GDPR, the European Union’s data protection regulation. Confusingly, at leat for US Americans not accustomed to data protection getting in the way of business, the European Union extends certain rights to individuals residing within its boundaries when it comes to how their personal data is used.
One of those rights, commonly referred to as the “Right to be Forgotten”, allows individuals to revoke their consent to storing and processing their personal data from companies, and with that removing the legal basis for those companies to continue storing or using it. The company - individual mapping here is important, because it explains why Microsoft’s Copilot (also powered by GPT4) is not affected - whichever “David Mayer” went through the pain of submitting the request (and it is painful, as we lay out below), decided to only go after OpenAI and not Microsoft or Perplexity.
Content not found
The content you are looking for could not be found. It may have been removed or is not available to you.
Primarily implemented through Article 17 of GDPR, it has been a key part of the regulation since it’s inception, and all major tech companies in the EU have implemented compliance in one form or another.
OpenAI, in fact, is providing the required mechanisms for users to inform them about the consent withdrawal via a sparse form linked from deep within their support system.
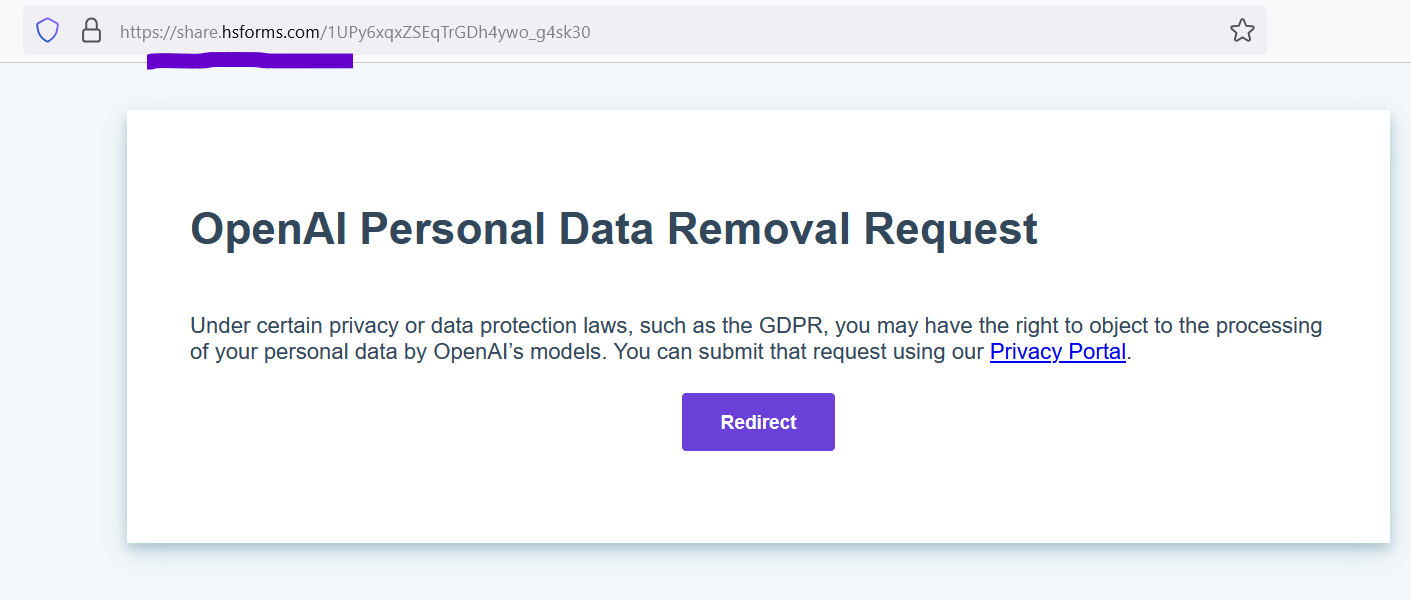
Hosted on nondescript third party domain, lacking any useful meta-data and with a robots exclusion header that explicitly disallows search engines to index it, it’s pretty clear that OpenAI is not trying to make it easy for users to submit requests to be forgotten.
In fact, at the time of writing, they seem to have made it basically impossible as the domain (privacy.openai.com) and page the form redirects to is not functional unless the user disables any adblockers or tracking protection they might have enabled.
All these “best practices” for inducing frictions aside, the fact that OpenAI is providing the opt out mechanisms tells us that the “David Mayer” issue is very likely related to their implementation of GDPR compliance, specifically “Right to be forgotten (see below).
Other reasons to block?
Of the names on the list (below) ‘Jonathan Turley’ and ‘Brian Hood’ have clear explanations. Both were at the receiving end of ChatGPT halluciation leading to defamation proceedings. The blocklist feature is used as a bandaid to prevent those responses. Whether OpenAI’s half-assed implementation (only blocking on the ChatGPT frontend, not the API and multi modal input) is enough to avoid legal problems here remains to be seen.
Content not found
The content you are looking for could not be found. It may have been removed or is not available to you.
MIT Professor “Jonathan Zittrain”, is also unmentionable. He a well known critic of the Right to be Forgotten, and is the author of a book called When Forgetting is not Best. He’s on record for not having filed a GDPR request, but has been writing critically about AI agents and is cited in the NYT’s copyright lawsuit with OpenAI.
Confirmed Names triggering the behavior
- David Mayer
- David Faber
- Brian Hood
- Jonathan Zittrain
- Jonathan Turley
- Guido Scorza
Technical Considerations
AI harm mitigation and compliance can happen at several levels of the AI stack:
Training Time Mitigations
- Pre-training time: Removing data from the initial training dataset (Rarely done so far due to the planetary scale of the training set).
- RLHF/Alignment time: Aligning the model to avoid specific content. (Done on sensitive, safety relevant content)
- Finetuning: In some situations, finetuning a model further to avoid specific content. (Possible but the tradeoffs make this a rarely used technique).
All these options have one thing in common: They are (prohibitively) expensive, slow to execute, not reliable and do not scale to potentially tens of thousands or more requests.
Inference Time (Cheaper, Faster)
- System Prompt: Adding a system prompt to the model to avoid specific content. (Done for example to induce diversity in the model’s output or push it away from copyright infringement. Costly and very limited as it has limited context and adds tokens to every prompt. Also very challenging to get right - famously the reason for Google’s challenges creating racially diverse WW2 soldiers).
- Inference time filtering: Filtering out specific content from the model’s input and output via more or less complex detction mechanism.
OpenAI chose option 5, and in particular a very cheap option there:
While there are other options (such as classifiers and guardian models), OpenAI chose to go with the cheapest option: blocking the offending term through an asynchronous, case insensitive exact match against a deny list, and doing it asynchronously to ensure it doesn’t impact latency.
Scalability, Weaponisation and Collateral Damage’
Even though fast, cheap and scalable (dictionary lookups have O(1) time complexity), the approach is not scalable for other reasons:
-
Scalability Even a mildly viral movement in the EU to block more names on the list would quickly lead to a situation where ChatGPT will refuse to reproduce an increasing amount of content, especially the moment web content is included in the response. If someone with a really generic name or that of an important politician were to enter the list, the impact would be significant.
-
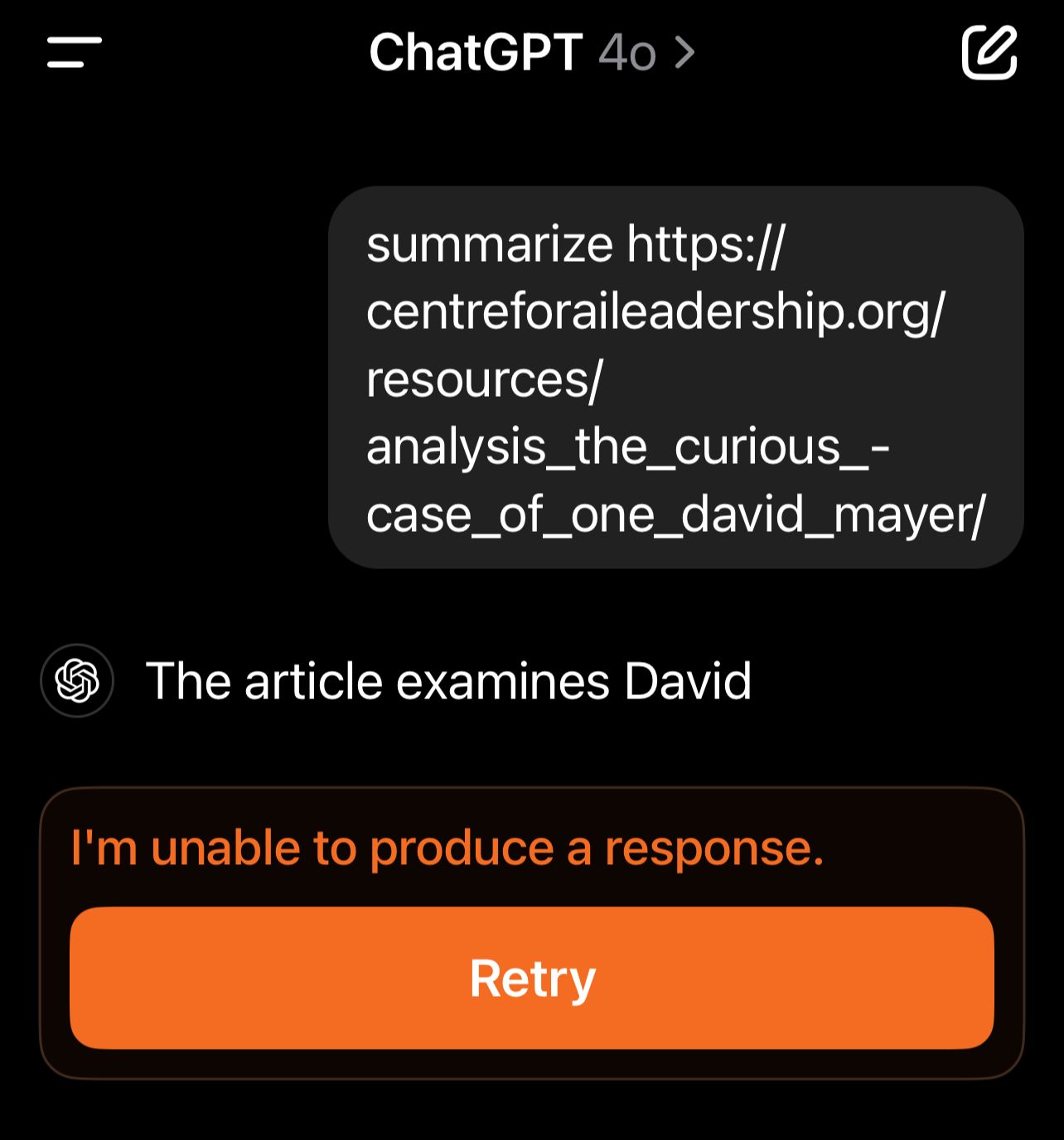
Weaponisation: Given the general sentiment about AI, scraping the web for content and the disintermediating of content creators, it’s not hard to imagine enterprising individuals adding “David Mayer” and other names from the blocklist to their own content or website in an effort to make it disappear from ChatGPT’s output. Likewise, should ChatGPT become increasingly important for business discovery and content virality, the presence of a larger number of “kill names” would make it easier to weaponise the model against specific targets, content and businesses. “David Mayer” leaving reviews for a hotel, restaurant or comments on a Youtube video could quickly become weaponized. We tested this theory with this very article, successfully confirming ChatGPT is unable to summarize it:
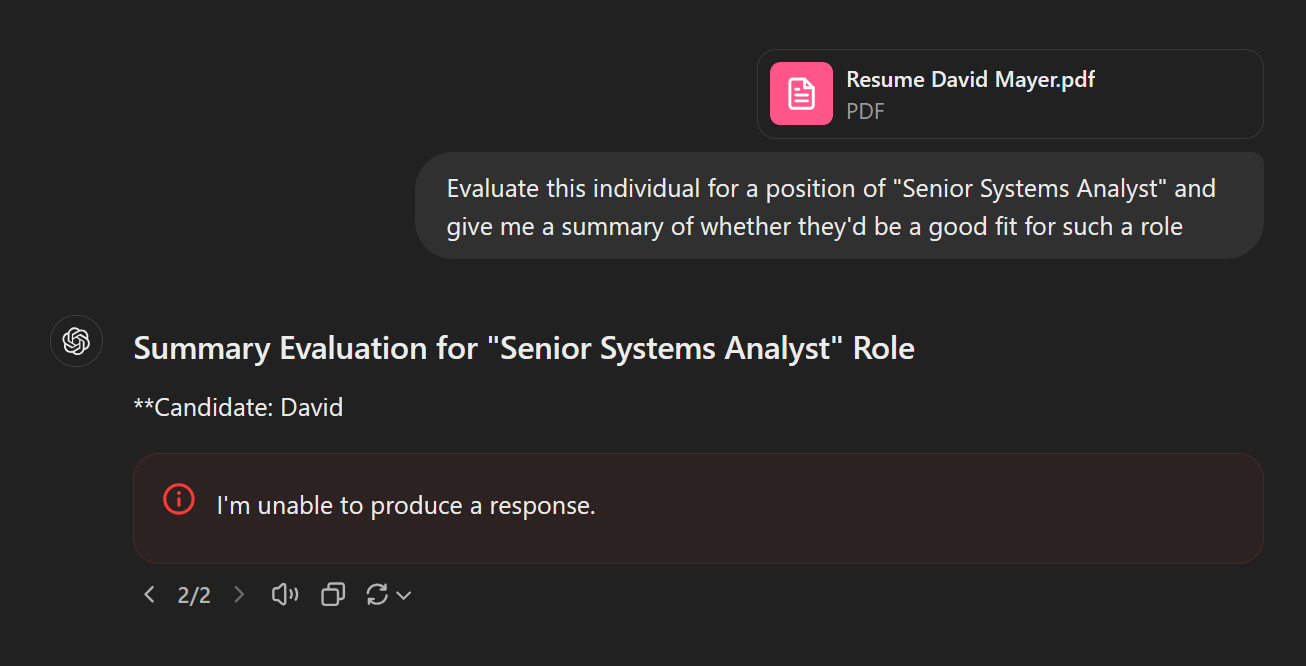
- Collateral Damage and Discrimination: Already, ChatGPT is used in many organisations, often in the form of “Shadow AI”, especially in HR and recruitment processes (despite it being a bad idea). The presence of a deny list in this context can and will lead to inadvertent collateral damage and discrimination against individuals. We performed a small experiment using an AI generated resume for one “David Mayer”, and confirmed that the model would refuse to generate content about the individual unless specifically instructed to avoid the offending name. With Generative AI and ChatGPT aggressively pushed for adoption, the risk of collateral damage for individuals sharing the same name (or even the individual who requested the removal) with discriminatory outcomes becomes a real concern.
- Denial of Service: The presence of a deny list can lead to denial of service on products and services.
Due to these issues, we estimate that OpenAI’s current solution is only GDPR compliant as long as the EU chooses to not enforce the letter of the law to avoid chilling effects on an emerging technology.
Questionable compliance
If the feature is in place to comply legal C&D orders, for example regarding defamation, the leaky implementation is likely not sufficient remedy to avoid consequences.
Likewise, GDPR compliance is not optional and applies to all residents of the European Union. As as such, is challenging to implement on a regional basis” A user relocating to the EU, for example, will be covered by the regulation from the moment they take residency - and so most companies choose to apply the regulation globally rather than dealing with all the edge cases. Nevertheless, all large companies have come into compliance over the last few years, inspired by hard hitting fines.
GDPR compliance for AI models however, is on a challenge on a whole new level: Not only are AI model providers engaged in indiscriminate scraping of data from the internet - data that includes data about people from all over the world, including Europe, they also encode this data in AI models that are, at current point in time, essentially immutable. No scalable mechanism exists to update a model reliably to remove data from a large scale LLM and retraining it to remove data would be, at least in the eyes of the training companies, commercially infeasible. In any case, retraining the model after each new request would be impossible.
As it stands, the technology is not able to meet the letter of the law and the industry is operating under the assumption that the regulation will not be enforced and eventually carve-outs will be provided or existing carve-outs (such for research and development) will protect them (OpenAI’s privacy request page, as seen below, invokes non profit research and development prominently).
As a layman, it scope limitation of OpenAI’s privacy request mechanism to “This portal only accepts requests from users of ChatGPT, DALL·E , and any other OpenAI services meant for individuals.” is likely designed to force people under the Terms of Service of these applications (a common legal practice in the US to reduce liability) and of questionable legality when it comes to GDPR compliance.
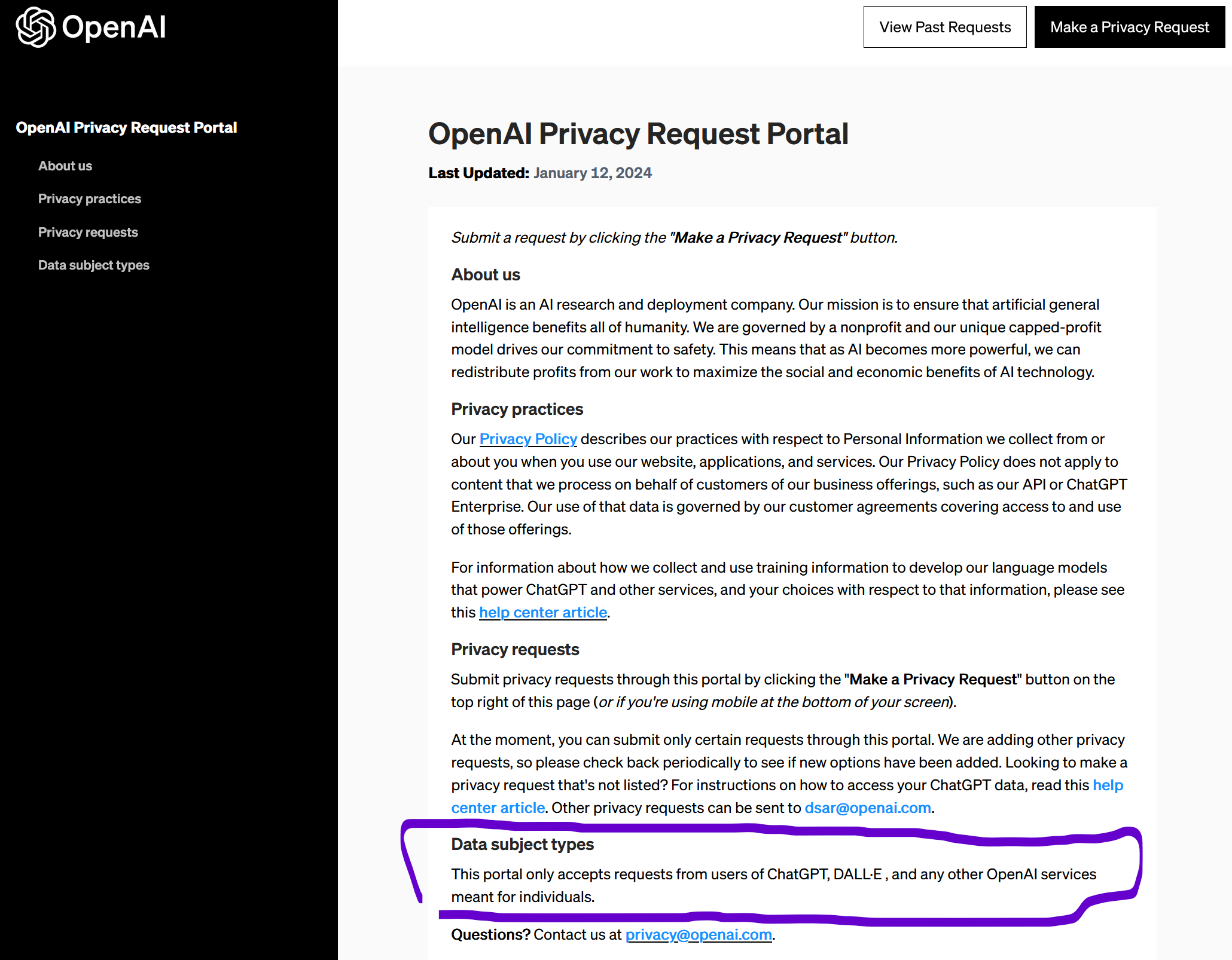
Attempts to actually log into the portal via email failed, unlike other parts of OpenAI’s operation, this one is clearly not a priority … I wonder why. The page confusingly lists an email address for other requests,so we are unable to test if it’s possible to submit requests to be forgotten via that channel.
Hallucinations create an additional problem. European regulation explicitly grants the right to correct incorrect information about oneself. If a model produces incorrect information about an individual, the individual has the right to request that the information be corrected - an easy tasks in a reproducible software system, an impossibility for transformer based AI models.
The paper “Right to be forgotten in the Era of large language models: implications, challenges, and solutions” (linked below), goes into significant detail about these challenges
Hallucination. Large language models may output factually incorrect content, which is known as “hallucination” [18], and producing such output does not require factually incorrect information to be present in the training dataset. Even if the context is given, the LLM-based generative search engines are possible [sic] to give incorrect citations, or draw wrong conclusions from the context [19]. Even though companies adopt guardrails and sophisticated prompts to minimize the rate of hallucination, hallucination is still unavoidable.
We produced an example of hallucination using ChatGPT (GPT-4) on 1 April 2024 as shown in the linksFootnote 17.Footnote 18 With identical prompts as input asking about a late professor in medicinal chemistry, ChatGPT provided different but both inaccurate information in two conversations, including the authorship information and death date.
Content not found
The content you are looking for could not be found. It may have been removed or is not available to you.
OpenAI’s specific implementation of GDPR compliance issues
-
While advertising multi-modal models able to understand audio, image and video content, the blacklist only blocks text. We successfully validated that ChatGPT Advanced Voice mode will happily respond to questions about “David Mayer” (while the legacy “audio input” mode will not, likely because it’s going through transcription first) and we were able to bypass the filter using a variety of other techniques including images, pdfs and code.
-
The filtering is not enforced on the API level, only on the web interface, but GDPR does not have an API carve-out.
-
As discussed earlier, the current implementation of the deny list mechanism can lead to collateral damage and discriminatory outcomes, possibly violating other regulation.
-
The lack of transparency from OpenAI (Google for example clearly indicates when it takes down content for GDPR reasons) is also troubling, creating not only this viral saga and conspiracy theories, but also raises suspicions about why the company is not attributing the reason for the termination of the conversation to the regulator, a common practice in the industry and way to avoid blame.
Final thoughts
The feature is likely a multi purpose bandaid for a number of regulatory, compliance and legal issues arising from LLM architecture. GDPR almost certainly is involved as OpenAI has an intake mechanisms for these requests and pre/post-processing mechanism for inference time filtering appears the only viable way to achieve compliance on LLMS at this time. Other, compliance requirements or legal obligation could also be at play, reusing the same mechanism.
Given all of the above, any David Mayer in the world could have submitted the request, there is no way to tell which one. It was very likely not everyone’s favourite suspect, since it would have a lot more sense to block “David de Rothschild” instead, which it does not.

The whole saga however is a good reminder of the challenges faced with making a very early stage technology that is aggressively pushed for adoption and commercialisation, compatible with the expectations of regulators and the public.
The crude, low effort blocklist implementation highlighted by the “David Mayer” saga and its very obvious negative externalities and long term risks associated with is, along with the lack of transparency from OpenAI not only reinforce the perception that OpenAI is playing fast and loose with safety, they also raises questions about the company’s ability to handle the more nuanced aspects of AI harm mitigation and compliance.
Coming from a highly sophisticated technology company obsessed with scaling and promising “superhuman intelligence” this could be read as an indicator of malicious compliance by regulators, especially if the negative consequences of scaling the solution start affecting other users.
About the Author
Georg Zoeller is a co-founder of Centre for AI Leadership and former Meta Business Engineering Director.